3. Hydrological modelling - Raven (distributed)¶
xHydro provides a collection of functions designed to facilitate hydrological modelling, focusing on two key models: HYDROTEL and a suite of models emulated by the Raven Hydrological Framework. It is important to note that Raven already possesses an extensive Python library, RavenPy, which enables users to build, calibrate, and execute models.
xHydro wraps some of these functions to support multi-model assessments with HYDROTEL, though users seeking advanced functionalities may prefer to use RavenPy directly.
The primary contribution of xHydro to hydrological modelling is thus its support for HYDROTEL, a model that previously lacked a dedicated Python library. This Notebook covers RavenPy models, but a similar notebook for HYDROTEL is available here.
3.1. Basic information¶
[1]:
from IPython.display import clear_output
import xhydro as xh
import xhydro.modelling as xhm
clear_output(wait=False)
The xHydro modelling framework is based on a model_config dictionary, which is meant to contain all necessary information to execute a given hydrological model. For example, depending on the model, it can store meteorological datasets directly, paths to datasets (netCDF files or other), csv configuration files, parameters, and basically anything that is required to configure and execute an hydrological model.
The list of required inputs for the dictionary can be obtained one of two ways. The first is to look at the hydrological model’s class, such as xhydro.modelling.RavenpyModel. The second is to use the xh.modelling.get_hydrological_model_inputs function to get a list of the required keys for a given model, as well as the documentation.
[3]:
Help on function get_hydrological_model_inputs in module xhydro.modelling.hydrological_modelling:
get_hydrological_model_inputs(model_name: str, required_only: bool = False) -> tuple[dict, str]
Get the required inputs for a given hydrological model.
Parameters
----------
model_name : str
The name of the hydrological model to use.
Currently supported models are ["HYDROTEL", "Blended", "GR4JCN", "HBVEC", "HMETS", "HYPR", "Mohyse", "SACSMA"].
required_only : bool
If True, only the required inputs will be returned.
Returns
-------
dict
A dictionary containing the required configuration for the hydrological model.
str
The documentation for the hydrological model.
[4]:
# This function can be called to get a list of the keys for a given model, as well as its documentation.
inputs, docs = xhm.get_hydrological_model_inputs("HBVEC", required_only=False)
inputs
[4]:
{'model_name': typing.Literal['Blended', 'GR4JCN', 'HBVEC', 'HMETS', 'HYPR', 'Mohyse', 'SACSMA'] | None,
'overwrite': bool,
'workdir': str | os.PathLike | None,
'executable': str | os.PathLike | None,
'run_name': str | None,
'start_date': datetime.datetime | str | None,
'end_date': datetime.datetime | str | None,
'parameters': numpy.ndarray | list[float] | None,
'qobs_file': os.PathLike | str | None,
'alt_name_flow': str | None,
'hru': geopandas.geodataframe.GeoDataFrame | dict | os.PathLike | str | None,
'output_subbasins': typing.Literal['all', 'qobs'] | list[int] | None,
'minimum_reservoir_area': str | None,
'meteo_file': os.PathLike | str | None,
'data_type': list[str] | None,
'alt_names_meteo': dict | None,
'meteo_station_properties': dict | None,
'gridweights': str | os.PathLike | None}
[5]:
print(docs)
Initialize the RavenPy model class.
Parameters
----------
overwrite : bool
If True, overwrite the existing project files. Default is False.
workdir : str | Path | None
Path to save the .rv files and model outputs. Default is None, which creates a temporary directory.
executable : str | os.PathLike | None, optional
Path to the Raven executable, bypassing RavenPy.
If None (default), the Raven executable from your current Python environment ('raven-hydro') will be used.
run_name : str, optional
Name of the run, which will be used to name the project files. Defaults to "raven" if not provided.
model_name : {"Blended", "GR4JCN", "HBVEC", "HMETS", "HYPR", "Mohyse", "SACSMA"}, optional
The name of the RavenPy model to run. Only optional if the project files already exist.
start_date : dt.datetime | str, optional
The first date of the simulation. Only optional if the project files already exist.
end_date : dt.datetime | str, optional
The last date of the simulation. Only optional if the project files already exist.
parameters : np.ndarray | list[float], optional
The model parameters for simulation or calibration. Only optional if the project files already exist.
qobs_file : str | Path, optional
Path to the file containing the observed streamflow data.
If there are multiple stations, the file should contain a 'basin_id' variable that identifies the subbasin for each time series.
If a 'station_id' variable is present, it will be used to identify the station.
alt_name_flow : str, optional
Name of the streamflow variable in the observed data file. If not provided, it will be assumed to be "q".
hru : gpd.GeoDataFrame | dict | os.PathLike, optional
A GeoDataFrame, or dictionary containing the HRU properties. Only optional if the project files already exist.
For distributed models, it should be readable by ravenpy.extractors.BasinMakerExtractor.
For lumped models, should contain the following variables:
- area: The watershed drainage area, in km².
- elevation: The elevation of the watershed, in meters.
- latitude: The latitude of the watershed centroid.
- longitude: The longitude of the watershed centroid.
- HRU_ID: The ID of the HRU (required for gridded data, optional for station data).
If the meteorological data is gridded, the HRU dataset must also contain a SubId, DowSubId, valid geometry and crs.
If the input is modified, a new shapefile will be created in the workdir/weights subdirectory.
output_subbasins : {"all", "qobs"} | list[int] | None, optional
If "all", all subbasins will be outputted. If "qobs", only the subbasins with observed flow will be outputted.
Leave as None to use the value as defined in the HRU file ('Has_Gauge' column). Only applicable for distributed HBVEC models.
minimum_reservoir_area : str, optional
Quantified string (e.g. "20 km2") representing the minimum lake area to consider the lake explicitly as a reservoir.
If not provided, all lakes with the 'HRU_IsLake' column set to 1 in the HRU file will be considered as reservoirs.
Note that 'reservoirs' in Raven can also refer to natural lakes with weir-like outflows.
Only applicable for distributed HBVEC models.
meteo_file : str | Path, optional
Path to the file containing the observed meteorological data. Only optional if the project files already exist.
The meteorological data can be either station or gridded data. Use the 'xhydro.modelling.format_input' function to ensure the data
is in the correct format. Unless the input is a single station accompanied by 'meteo_station_properties', the file should contain
the following coordinates:
- elevation: The elevation of the station / grid cell, in meters.
- latitude: The latitude of the station / grid cell centroid.
- longitude: The longitude of the station / grid cell centroid.
data_type : list[str], optional
The list of types of data provided to Raven in the meteorological file. Only optional if the project files already exist.
See https://github.com/CSHS-CWRA/RavenPy/blob/master/src/ravenpy/config/conventions.py for the list of available types.
alt_names_meteo : dict, optional
A dictionary that allows users to link the names of meteorological variables in their dataset to Raven-compliant names.
The keys should be the Raven names as listed in the data_type parameter.
meteo_station_properties : dict, optional
Additional properties of the weather stations providing the meteorological data. Only required if absent from the 'meteo_file'.
For single stations, the format is {"ALL": {"elevation": elevation, "latitude": latitude, "longitude": longitude}}.
This has not been tested for multiple stations or gridded data.
gridweights : str | Path | None
If using gridded meteorological data, path to a text file containing the weights linking the grid cells to the HRUs.
If None, the weights will be computed using ravenpy.extractors.GridWeightExtractor and saved in a 'weights' subdirectory
of the project folder, using a "{meteo_file}_vs_{hru_file}_weights.txt" pattern.
\*\*kwargs : dict, optional
Additional parameters to pass to the RavenPy emulator, to modify the default modules used by a given hydrological model.
Typical entries include RainSnowFraction, Evaporation, GlobalParameters, etc.
See https://raven.uwaterloo.ca/Downloads.html for the latest Raven documentation. Currently, model templates are listed in Appendix F.
HYDROTEL and Raven vary in terms of required inputs and available functions, but an effort will be made to standardize the outputs as much as possible. Currently, all models include the following three functions:
.run(): Executes the model, reformats the outputs to be compatible with analysis tools inxHydro, and returns the simulated streamflow as axarray.Dataset.The streamflow variable will be named
qand will have units ofm3 s-1.For 1D data (such as hydrometric stations), the corresponding dimension in the dataset will be identified by the
cf_role: timeseries_idattribute.
.get_inputs(): Retrieves the meteorological inputs used by the model..get_outputs(): Retrieves the simulated outputs from the model.Use
.get_outputs("q")to obtain the simulated streamflow as axarray.Dataset.
.standardize_outputs(): Standardizes the outputs to ensure consistency across different models, facilitating comparison and analysis. This function is used by default in the.run()method, but can also be called separately if needed.
3.2. Initializing and running a calibrated model¶
Raven requires several .rv* files to control various aspects such as meteorological inputs, watershed characteristics, and more. If the project directory already exists and contains data, xHydro will prepare the model for execution without overwriting existing .rv* files—unless the overwrite argument is explicitly set to True. To force overwriting of these files, you can thus either:
Set
overwrite=Truein themodel_configwhen instantiating the modelUse the
.create_rv(overwrite=True)method on the instantiated model.
This Notebook will focus on distributed RavenPy models. For lumped models, refer to the Raven lumped modelling notebook.
3.2.1. Formatting HRU Data for distributed models¶
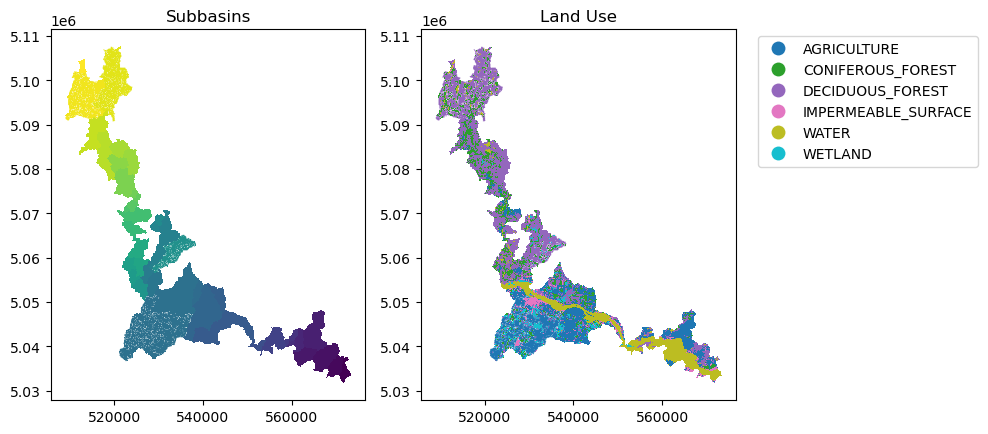
Raven relies on Hydrological Response Units (HRUs) for its hydrological simulations, which are typically generated using the BasinMaker tool, and specifically its .Generate_HRUs function. Thus, xHydro’s distributed modelling is currently based on the BasinMaker HRU structure and nomenclature, and uses the BasinMakerExtractor class of RavenPy to extract the necessary HRU attributes from a shapefile.
Additionally, while BasinMaker will produce attributes such as Landuse_ID, these will not be passed on to the RavenPy model. Instead, the HRU should contain relevant land use attributes that can be directly mapped to the hydrological model’s arguments. For example, for the HBV-EC model, which is currently the only distributed model available in Raven, the following attributes are used instead: LAND_USE_C, VEG_C, and SOIL_PROF, which represent land use, vegetation, and
soil profile respectively.
INFO
By default, HBV-EC as defined in RavenPy only understands a unique LAND_USE_C (LU_ALL), VEG_C (VEG_ALL), and SOIL_PROF (DEFAULT_P). If you want to use different classes, you will need to modify the model_config dictionary to include the relevant keys. There is currently no good documentation on how to do this, but you can refer to the class definition of the HBVEC model in ravenpy.config.emulators.hbvec.py.
As an example, new vegetation classes can be added by modifying the VegetationClasses and VegetationParameterList keys with new entries detailing all the vegetation classes and their parameters. The same applies to land use and soil profile classes.
[6]:
from pathlib import Path
import geopandas as gpd
import matplotlib.pyplot as plt
import pooch
from xhydro.testing.helpers import ( # In-house function to get data from the xhydro-testdata repo
deveraux,
)
df = gpd.read_file(
Path(
deveraux().fetch(
"ravenpy/hru_subset.zip",
pooch.Unzip(),
)[0]
).parents[0]
)
# Plot the subbasins and land use
f, ax = plt.subplots(1, 2, figsize=(10, 10))
df.plot(column="SubId", ax=ax[0])
ax[0].set_title("Subbasins")
df.plot(
column="LAND_USE_C",
ax=ax[1],
legend=True,
legend_kwds={"bbox_to_anchor": (1.05, 1), "loc": "upper left"},
)
ax[1].set_title("Land Use")
plt.tight_layout()
[7]:
# To keep this example simple, and until cleaner methods are incorporated in xHydro, we will revert to the default HBVEC model configuration.
# This is not recommended for real applications, as you will likely want to modify the model configuration to suit your needs.
df.loc[:, "LAND_USE_C"] = "LU_ALL"
df.loc[:, "VEG_C"] = "VEG_ALL"
df.loc[:, "SOIL_PROF"] = "DEFAULT_P"
3.2.2. Formatting Meteorological Data¶
INFO
If using multiple meteorological stations, it is recommended to add the Interpolation argument to model_config or the RavenpyModel call to control the interpolation algorithm. Raven uses the nearest neighbour method by default, but other options are available:
INTERP_NEAREST_NEIGHBOR(default) — Nearest neighbor (Voronoi) methodINTERP_INVERSE_DISTANCE— Inverse distance weightingINTERP_INVERSE_DISTANCE_ELEVATION— Inverse distance weighting with consideration of elevationINTERP_AVERAGE_ALL— Averages all specified gauge readingsINTERP_FROM_FILE [filename]— Weights for each gauge at each HRU are specified in an external file. This method should work viaxHydro, but it has not been fully tested.
INFO
xHydro uses functions from RavenPy to compute weights for each grid cell based on the HRU’s geometry.The acquisition of raw meteorological data is covered in the GIS notebook and Use Case Example notebooks. Therefore, this notebook will use a test dataset.
[8]:
import xarray as xr
ds = xr.open_zarr(
Path(
deveraux().fetch(
"pmp/CMIP.CCCma.CanESM5.historical.r1i1p1f1.day.gn.zarr.zip",
pooch.Unzip(),
)[0]
).parents[0]
)
ds_fx = xr.open_zarr(
Path(
deveraux().fetch(
"pmp/CMIP.CCCma.CanESM5.historical.r1i1p1f1.fx.gn.zarr.zip",
pooch.Unzip(),
)[0]
).parents[0]
)
ds["orog"] = ds_fx["orog"]
ds = ds.drop_vars(["height"])
ds["pr"].attrs = {"units": "mm", "long_name": "precipitation"}
ds = ds[["pr", "tas", "orog"]]
ds
[8]:
<xarray.Dataset> Size: 85kB
Dimensions: (time: 730, y: 3, x: 3)
Coordinates:
* time (time) object 6kB 2010-01-01 12:00:00 ... 2011-12-31 12:00:00
* y (y) float64 24B 43.25 46.04 48.84
* x (x) float64 24B 281.2 284.1 286.9
Data variables:
pr (time, y, x) float64 53kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
tas (time, y, x) float32 26kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
orog (y, x) float32 36B dask.array<chunksize=(3, 3), meta=np.ndarray>
Attributes: (12/56)
CCCma_model_hash: 3dedf95315d603326fde4f5340dc0519d80d10c0
CCCma_parent_runid: rc3-pictrl
CCCma_pycmor_hash: 33c30511acc319a98240633965a04ca99c26427e
CCCma_runid: rc3.1-his01
Conventions: CF-1.7 CMIP-6.2
YMDH_branch_time_in_child: 1850:01:01:00
... ...
title: CanESM5 output prepared for CMIP6
tracking_id: hdl:21.14100/d0a84c86-7fb1-4de4-8837-574504c...
variable_id: hus
variant_label: r1i1p1f1
version: v20190429
version_id: v20190429Every hydrological model has different requirements when it comes to their input data. In this example, the data above has multiple issues that would be not compatible with the requirements for Raven. For reference on default units expected by Raven, consult this link.
The function xh.modelling.format_input can be used to reformat CF-compliant datasets for use in hydrological models.
[9]:
Help on function format_input in module xhydro.modelling.hydrological_modelling:
format_input(
ds: xr.Dataset,
model: str,
convert_calendar_missing: float | str | dict | bool = nan,
save_as: str | PathLike | None = None,
**kwargs
) -> tuple[xr.Dataset, dict]
Reformat CF-compliant meteorological data for use in hydrological models. See the "Notes" section for important details.
Parameters
----------
ds : xr.Dataset
A dataset containing the meteorological data. See the "Notes" section for more information on the expected format.
model : str
The name of the hydrological model to use.
Currently supported models are:
- "HYDROTEL", "Raven" (which is an alias for all RavenPy models), "Blended", "GR4JCN", "HBVEC", "HMETS", "HYPR", "Mohyse", "SACSMA".
convert_calendar_missing : float | str | dict | bool, optional
The value to use for missing values when converting the calendar to "standard".
If the value is a float, it will be used as the fill value for all variables.
If the value is a string "interpolate", the new dates will be linearly interpolated over time.
A dictionary can be used to specify a different fill value for each variable.
Keys should be the names of the variables as they appear in the first entry in the "variable_name" lists of the "Notes" section.
If True, temperatures will be interpolated and precipitation will be filled with 0.
If False, the calendar will not be converted. Only possible for "Raven" models.
save_as : str, optional
Where to save the reformatted data. If None, the data will not be saved.
This can be useful when multiple files are needed for a single model run (e.g. HYDROTEL needs a configuration file).
\*\*kwargs : dict
Additional keyword arguments to pass to the save function.
Returns
-------
xr.Dataset
The reformatted dataset.
dict
For HYDROTEL, a dictionary containing the configuration for the meteorological data.
If `save_as` is provided, the configuration will have been saved to a file with the same name as `save_as`, but with a ".nc.config" extension.
For Raven, a dictionary containing the 'data_type' and 'alt_names_meteo' keys required for the 'model_config' argument.
Notes
-----
The input dataset should ideally be CF-compliant and follow CMIP6's Controlled Vocabulary, but this function will attempt to detect the
variables based on the standard_name attribute, the cell_methods attribute, or the variable name.
More information on those attributes can be found here: https://wcrp-cmip.org/cmip-model-and-experiment-documentation/, and specifically
the 'CMIP6 MIP table' link provided in the 'Search for variables' section.
Specifically:
- If using 1D time series, the station dimension should have an attribute `cf_role` set to "timeseries_id".
- Units don't need to be canonical, but they should be convertible to the expected units and be understood by `xclim`.
- Elevation represents the altitude of the meteorological data / model grid cell, not the altitude of the ground.
- Snowfall units should be in water equivalent of precipitation (e.g. mm/day or kg/m²/s), NOT height (e.g. cm of fresh snow on the ground).
- The function will try to detect the variables based on the attributes and the variable name. The following attempts will be made:
- Longitude:
- standard_name: "longitude"
- variable name: "longitude", "lon"
- Latitude:
- standard_name: "latitude"
- variable name: "latitude", "lat"
- Elevation:
- standard_name: "surface_altitude"
- variable name: "elevation", "orog", "z", "altitude", "height"
- Precipitation:
- standard_name: "*precipitation*" (e.g. "lwe_thickness_of_precipitation_amount")
- variable name: "pr", "precip", "precipitation"
- Rainfall:
- standard_name: "*rainfall*" (e.g. "rainfall_flux", "rainfall_amount")
- variable name: "prra", "prlp", "rainfall", "rain", "precipitation_rain"
- Snowfall:
- standard_name: "*snowfall*" (e.g. "snowfall_flux", "snowfall_amount")
- variable name: "prsn", "snowfall", "precipitation_snow"
- Maximum temperature:
- standard_name: "air_temperature"
- cell_methods: "time: maximum"
- variable name: "tasmax", "tmax", "t2m_max", "temperature_max"
- Minimum temperature:
- standard_name: "air_temperature"
- cell_methods: "time: minimum"
- variable name: "tasmin", "tmin", "t2m_min", "temperature_min"
- Mean temperature:
- standard_name: "air_temperature"
- cell_methods: "time: mean"
- variable name: "tas", "tmean", "t2m", "temperature_mean"
HYDROTEL requires the following variables: ["longitude", "latitude", "elevation", "time", "tasmax", "tasmin", "pr"].
Raven requires the following variables: ["longitude", "latitude", "elevation", "time", "tasmax/tasmin" or "tas", "pr" or "prlp/prsn"].
[10]:
from pathlib import Path
import tempfile
notebook_folder = Path(tempfile.TemporaryDirectory().name)
# You can also use the 'save_as' argument to save the new file(s) in your project folder.
ds_reformatted, config = xh.modelling.format_input(
ds,
"HBVEC",
save_as=notebook_folder / "_data" / "meteo_hmr_distributed.nc",
)
ds_reformatted
/tmp/ipykernel_5404/2541478589.py:6: UserWarning: The calendar 'noleap' needs to be converted to 'standard', but 'convert_calendar_missing' is set to np.nan. NaNs will need to be filled manually before running HYDROTEL or Raven.
/home/docs/checkouts/readthedocs.org/user_builds/xhydro/conda/stable/lib/python3.14/site-packages/clisops/utils/dataset_utils.py:1853: UserWarning: For coordinate variable 'longitude' no bounds can be identified.
[10]:
<xarray.Dataset> Size: 85kB
Dimensions: (time: 730, latitude: 3, longitude: 3)
Coordinates:
* time (time) datetime64[ns] 6kB 2010-01-01T12:00:00 ... 2011-12-31T1...
* latitude (latitude) float64 24B 43.25 46.04 48.84
* longitude (longitude) float64 24B -78.75 -75.94 -73.12
elevation (latitude, longitude) float32 36B dask.array<chunksize=(3, 3), meta=np.ndarray>
Data variables:
pr (time, latitude, longitude) float64 53kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
tas (time, latitude, longitude) float32 26kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
Attributes: (12/56)
CCCma_model_hash: 3dedf95315d603326fde4f5340dc0519d80d10c0
CCCma_parent_runid: rc3-pictrl
CCCma_pycmor_hash: 33c30511acc319a98240633965a04ca99c26427e
CCCma_runid: rc3.1-his01
Conventions: CF-1.7 CMIP-6.2
YMDH_branch_time_in_child: 1850:01:01:00
... ...
title: CanESM5 output prepared for CMIP6
tracking_id: hdl:21.14100/d0a84c86-7fb1-4de4-8837-574504c...
variable_id: hus
variant_label: r1i1p1f1
version: v20190429
version_id: v20190429While RavenPy does not require a configuration file to accompany the meteorological file, many information must be given to model_config to properly instantiate the model. The second output of format_input will return the “meteo_file”, “data_type”, “alt_names_meteo”, and “meteo_station_properties” entries based on the provided file.
[11]:
config
[11]:
{'data_type': ['TEMP_AVE', 'PRECIP'],
'alt_names_meteo': {'TEMP_AVE': 'tas', 'PRECIP': 'pr'},
'meteo_file': '/tmp/tmp3zfitsfm/_data/meteo_hmr_distributed.nc'}
3.2.3. Initializing the Model¶
model_config dictionary, as long as they are supported by the emulated Raven model. In particular:The
output_subbasinskey can be used to specify which subbasins to output.The
global_parameterkey must have a value forAVG_ANNUAL_RUNOFF, which is the average annual runoff in mm/year (with a range of 0-1000 according the Raven’s documentation). This value is required for distributed models.
[12]:
# The HBVEC model has 21 parameters
parameters = [
-0.15,
3.5,
3.0,
0.07,
0.4,
0.8,
1,
4.0,
0.5,
0.1,
1,
5.0,
4.8,
0.1,
1.0,
22.0,
0.5,
0.1,
0.0,
1.0,
1.0,
]
model_config = {
"model_name": "HBVEC",
"workdir": notebook_folder / "hbvec_distributed_simulation",
"parameters": parameters,
"global_parameter": {
"AVG_ANNUAL_RUNOFF": 597
}, # Distributed models require an average annual runoff value at each HRU
"hru": df,
"output_subbasins": "all", # Use "all" to output all subbasins
"start_date": "2010-01-02",
"end_date": "2010-12-31",
"Evaporation": "PET_HARGREAVES",
**config,
}
With model_config on hand, an instance of the hydrological model can be initialized using xhydro.modelling.hydrological_model or the xhydro.modelling.RavenpyModel class directly.
[13]:
hm = xhm.hydrological_model(model_config)
hm
[13]:
<xhydro.modelling._ravenpy_models.RavenpyModel at 0x7fcd52b4b230>
3.2.4. Validating the Meteorological Data¶
Before executing hydrological models, a few basic checks will be performed automatically. However, users may want to conduct more advanced health checks on the meteorological inputs (e.g., identifying unrealistic values). This can be done using xhydro.utils.health_checks. For the full list of available checks, refer to the ‘xscen’ documentation.
We can use .get_inputs() to automatically retrieve the meteorological data. In this example, we’ll ensure there are no abnormal meteorological values or sequences of values.
[14]:
health_checks = {
"raise_on": [], # If an entry is not here, it will warn the user instead of raising an exception.
"flags": {
"pr": { # You can have specific flags per variable.
"negative_accumulation_values": {},
"very_large_precipitation_events": {},
"outside_n_standard_deviations_of_climatology": {"n": 5},
"values_repeating_for_n_or_more_days": {"n": 5},
},
"tas": {
"temperature_extremely_low": {},
"temperature_extremely_high": {},
"outside_n_standard_deviations_of_climatology": {"n": 5},
"values_repeating_for_n_or_more_days": {"n": 5},
},
},
}
[15]:
from xclim.core.units import amount2rate
with hm.get_inputs() as ds_in:
ds_in["pr"] = amount2rate(ds_in["pr"]) # Precipitation in xclim needs to be a flux.
xh.utils.health_checks(ds_in, **health_checks)
3.2.5. Executing the Model¶
A few basic checks are performed when the .run() function is called, before executing the model itself. However, since both RavenPy and Raven will perform a series of checkups themselves, they are kept at a minimum in xHydro. If required, a RavenpyModel.executable class attribute can be used to point to your own Raven executable instead of the one provided by the raven-hydro library in the active Python environment.
Once the model is executed, xHydro will automatically reformat the NetCDF file to bring it closer to CF conventions, ensuring compatibility with other xHydro modules. Note that, at this time, only the streamflow variable is reformatted, as the modularity of Raven allows for a wide variety of outputs, and it is not yet clear how to standardize all of them. However, dimensions and coordinates will be standardized across all files.
[16]:
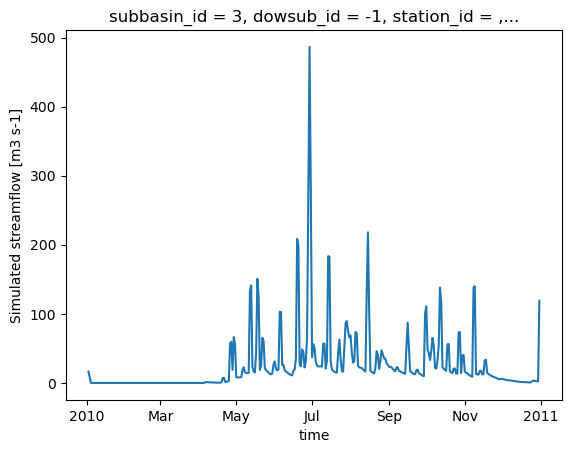
ds_out = hm.run()
ds_out
[16]:
<xarray.Dataset> Size: 74kB
Dimensions: (time: 364, subbasin_id: 47)
Coordinates:
* time (time) datetime64[ns] 3kB 2010-01-02 ... 2010-12-31
* subbasin_id (subbasin_id) <U2 376B '3' '4' '5' '6' ... '47' '48' '49'
dowsub_id (subbasin_id) <U2 376B ...
station_id (subbasin_id) <U6 1kB ...
drainage_area (subbasin_id) float64 376B ...
Data variables:
q (time, subbasin_id) float32 68kB ...
Attributes:
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-06-29T16:07:34 by Raven 4.12
description: Standard Output
references: Craig J.R. and the Raven Development Team Raven user's ...
model_id: HBVEC
Raven_version: 4.12
RavenPy_version: 0.21.0[17]:
ds_out.isel(subbasin_id=0)["q"].plot()
[17]:
[<matplotlib.lines.Line2D at 0x7fcd4271de80>]
3.3. Updating the rv* files¶
Currently, RavenPy provides no straightforward way to open and modify the Raven .rv* files. For instance, changing simulation dates or meteorological data directly through the files is not yet supported. Until this feature is added, some basic functions have been integrated into xHydro, but should be used with care.
The basic information, such as start_date, end_date, and parameters, are stored directly in the RavenpyModel class and can be manually updated. Similarly, if additional arguments had been given to the model during initialization, they are stored within a dictionary under RavenpyModel.kwargs, which can be accessed and modified as needed.
The observed streamflow, HRU characteristics and meteorological data are stored under the .qobs, .hru and .meteo attributes respectively, but can be much trickier to update, since the associated RavenPy commands must be reconstructed again. Therefore, it is strongly recommended to use the .update_data method to update these. This function calls upon a subset of the same arguments used when initializing a Raven model:
[18]:
help(hm.update_data)
Help on method update_data in module xhydro.modelling._ravenpy_models:
update_data(
*,
qobs_file: os.PathLike | str | None = None,
alt_name_flow: str | None = 'q',
hru: gpd.GeoDataFrame | dict | os.PathLike | str | None = None,
output_subbasins: Literal['all', 'qobs'] | list[int] | None = None,
minimum_reservoir_area: str | None = None,
meteo_file: os.PathLike | str | None = None,
data_type: list[str] | None = None,
alt_names_meteo: dict | None = None,
meteo_station_properties: dict | None = None,
gridweights: str | os.PathLike | None = None
) method of xhydro.modelling._ravenpy_models.RavenpyModel instance
Update the model configuration with new observed data (self.qobs), HRU properties (self.hru), or meteorological data (self.meteo).
Parameters
----------
qobs_file : os.PathLike | str
Path to the NetCDF file containing the observed streamflow data.
If there are multiple stations, the file should contain a 'basin_id' variable that identifies the subbasin for each time series.
If a 'station_id' variable is present, it will be used to identify the station.
alt_name_flow : str, optional
Alternative name for the streamflow variable in the observed data.
hru : gpd.GeoDataFrame | dict | os.PathLike | str
A GeoDataFrame, or dictionary containing the HRU properties. Alternatively, a path to a shapefile containing the HRU properties.
For distributed models, it should be readable by ravenpy.extractors.BasinMakerExtractor.
For lumped models, should contain the following variables:
- area: The watershed drainage area, in km².
- elevation: The elevation of the watershed, in meters.
- latitude: The latitude of the watershed centroid.
- longitude: The longitude of the watershed centroid.
- HRU_ID: The ID of the HRU (required for gridded data, optional for station data).
If the meteorological data is gridded, the HRU dataset must also contain a SubId, DowSubId, valid geometry and crs.
If the input is modified, a new shapefile will be created in the workdir/weights subdirectory.
output_subbasins : {"all", "qobs"} | list[int] | None, optional
If "all", all subbasins will be outputted.
If "qobs", subbasins with observed flow will be outputted, as defined by the basin IDs in the observed streamflow data.
If a list of integers is provided, it should contain the basin IDs to output.
Leave as None to use the value as defined in the HRU file ('Has_Gauge' column).
minimum_reservoir_area : str, optional
Quantified string (e.g. "20 km2") representing the minimum lake area to consider the lake explicitly as a reservoir.
If not provided, all lakes with the 'HRU_IsLake' column set to 1 in the HRU file will be considered as reservoirs.
Note that 'reservoirs' in Raven can also refer to natural lakes with weir-like outflows.
Only applicable for distributed HBVEC models.
meteo_file : str | Path, optional
Path to the file containing the observed meteorological data. Only optional if the project files already exist.
The meteorological data can be either station or gridded data. Use the 'xhydro.modelling.format_input' function to ensure the data
is in the correct format. Unless the input is a single station accompanied by 'meteo_station_properties', the file should contain
the following coordinates:
- elevation: The elevation of the station / grid cell, in meters.
- latitude: The latitude of the station / grid cell centroid.
- longitude: The longitude of the station / grid cell centroid.
data_type : list[str], optional
The list of types of data provided to Raven in the meteorological file. Only optional if the project files already exist.
See https://github.com/CSHS-CWRA/RavenPy/blob/master/src/ravenpy/config/conventions.py for the list of available types.
alt_names_meteo : dict, optional
A dictionary that allows users to link the names of meteorological variables in their dataset to Raven-compliant names.
The keys should be the Raven names as listed in the data_type parameter.
meteo_station_properties : dict, optional
Additional properties of the weather stations providing the meteorological data. Only required if absent from the 'meteo_file'.
For single stations, the format is {"ALL": {"elevation": elevation, "latitude": latitude, "longitude": longitude}}.
This has not been tested for multiple stations or gridded data.
gridweights : str | Path | None
If using gridded meteorological data, path to a text file containing the weights linking the grid cells to the HRUs.
If None, the weights will be computed using ravenpy.extractors.GridWeightExtractor and saved in a 'weights' subdirectory
of the project folder, using a "{meteo_file}_vs_{hru_file}_weights.txt" pattern.
Notes
-----
If the meteorological data is gridded, new weights will be computed using the HRU file in the RavenpyModel instance and saved
in a 'weights' subdirectory of the project folder, under the name 'meteo-name_vs_hru-name.txt'.
That function will only update the RavenpyModel class itself, not the files. If possible, it is strongly recommended to use the create_rv function to overwrite the existing .rv* files with the updated information.
If this is not possible, some aspects of the model can still be updated using the .update_config method:
[19]:
help(hm.update_config)
Help on method update_config in module xhydro.modelling._ravenpy_models:
update_config(
*,
rvi_dates: bool = False,
rvi_commands: list[str] | None = None,
rvt: bool = False,
rvh: bool = False
) -> None method of xhydro.modelling._ravenpy_models.RavenpyModel instance
Manually update some aspects of the configuration of the RavenPy model.
Parameters
----------
rvi_dates : bool
If True, update the .rvi file with the 'start_date' and 'end_date' defined in the model.
rvi_commands : list[str] | None
A list of commands to include in the .rvi file. If None, no additional commands will be added.
Warning: These commands will be added at the end of the .rvi file, with no checks. Use with caution.
rvt : bool
If True, update the .rvt file with the meteorological data and observed streamflow data defined in the model.
rvh : bool
If True, update the .rvh file with the list of subbasins to output. Nothing else will be changed in that file.
Notes
-----
Ideally, users should favor using the `update_data` method to update the model configuration, then call the `create_rv`
method to recreate the project files from scratch. This method assumes that the changes brought to the model configuration
are minimal, such as wanting to change the meteorological data or the simulation start and end dates.
Be aware that:
- The .rvh will be rewritten entirely. If multiple sources of data were mentioned, such as both meteorological and observed streamflow data,
all of them must be included in the RavenpyModel instance.
- If the meteorological data is gridded, new weights will be computed using the HRU file in the RavenpyModel instance. If that HRU
file is different from the one used to create the original .rvh file, it may lead to inconsistencies or errors.
- Similarly, only the list of subbasins to output will be modified in the new .rvh file. Any additional changes to the HRU or
other components might also lead to inconsistencies or errors.
A backup of the original files will be created before any modifications are made.
Be very aware that not all updates will be reflected in the .rv* files. The last two options especially should be used with caution, as HRU characteristics, such as the subbasin IDs, will not be updated. If the HRU within the model has changed, there is currently no way to modify existing files. They should be deleted and recreated using the .create_rv() method.
3.4. Retrieving additional outputs¶
By default, Raven produces multiple output files in addition to the streamflow file, which contain various state variables. However, a major limitation is that these files only cover the watershed as a whole, and not the individual HRUs or river segments. The :CustomOutput command can be used to specify additional outputs and their spatial resolution. The easiest way to generate these is to use the update_config method.
Information on how to use the :CustomOutput command can be found in the Raven documentation.
[20]:
hm.update_config(
rvi_commands=[":CustomOutput DAILY CUMULSUM SNOW BY_HRU"]
)
hm.run(overwrite=True, return_streamflow=False)
The .get_outputs() function can be used to retrieve any of these variables as a xarray.Dataset.
[21]:
help(hm.get_outputs)
Help on method get_outputs in module xhydro.modelling._ravenpy_models:
get_outputs(output: str, return_paths: bool = False, **kwargs) -> xr.Dataset | Path | list[Path] method of xhydro.modelling._ravenpy_models.RavenpyModel instance
Return the outputs of the Raven model.
Parameters
----------
output : str
"path" to return the output directory.
"q" to only return the streamflow variable.
Alternatively, a string matching the name of the output file to return (e.g. "Hydrographs", "Storage", "ByHRU", etc.).
Wildcards can be used.
return_paths : bool
If True, return the path to the output file(s) instead of the dataset. Default is False.
\*\*kwargs : dict
Keyword arguments to pass to :py:func:`xarray.open_dataset`.
Returns
-------
xr.Dataset
The requested output variable.
Path
The path to the output directory if output is set to "path".
list[Path]
The path to the output file(s) if return_path is True.
[22]:
files = hm.get_outputs("*", return_paths=True)
files
[22]:
[PosixPath('/tmp/tmp3zfitsfm/hbvec_distributed_simulation/output/raven_WatershedStorage.nc'),
PosixPath('/tmp/tmp3zfitsfm/hbvec_distributed_simulation/output/raven_SNOW_Daily_CumulSum_ByHRU.nc'),
PosixPath('/tmp/tmp3zfitsfm/hbvec_distributed_simulation/output/raven_Hydrographs.nc')]
[23]:
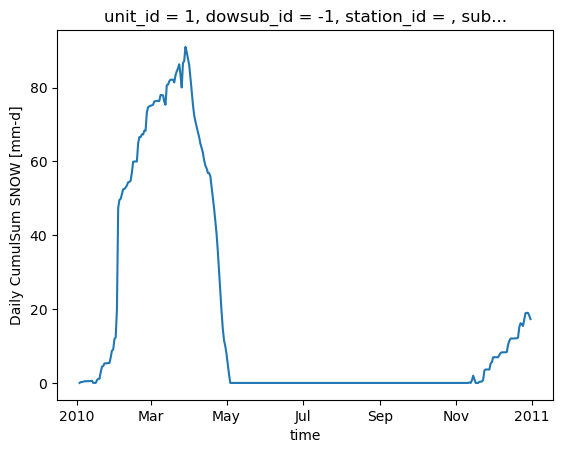
snow = hm.get_outputs("SNOW*")
snow
[23]:
<xarray.Dataset> Size: 265kB
Dimensions: (time: 363, unit_id: 166)
Coordinates: (12/14)
* time (time) datetime64[ns] 3kB 2010-01-03 ... 201...
* unit_id (unit_id) <U3 2kB '1' '2' '3' ... '165' '166'
dowsub_id (unit_id) <U2 1kB dask.array<chunksize=(166,), meta=np.ndarray>
station_id (unit_id) <U6 4kB dask.array<chunksize=(166,), meta=np.ndarray>
subbasin_id (unit_id) <U2 1kB dask.array<chunksize=(166,), meta=np.ndarray>
subbasin_centroid_longitude (unit_id) float64 1kB dask.array<chunksize=(166,), meta=np.ndarray>
... ...
unit_centroid_latitude (unit_id) float64 1kB dask.array<chunksize=(166,), meta=np.ndarray>
drainage_area (unit_id) float64 1kB dask.array<chunksize=(166,), meta=np.ndarray>
subbasin_drainage_area (unit_id) float64 1kB dask.array<chunksize=(166,), meta=np.ndarray>
unit_drainage_area (unit_id) float64 1kB dask.array<chunksize=(166,), meta=np.ndarray>
subbasin_elevation (unit_id) float64 1kB dask.array<chunksize=(166,), meta=np.ndarray>
unit_elevation (unit_id) float64 1kB dask.array<chunksize=(166,), meta=np.ndarray>
Data variables:
CumulSum_SNOW (time, unit_id) float32 241kB dask.array<chunksize=(1, 166), meta=np.ndarray>
Attributes:
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-06-29T16:07:34 by Raven 4.12
description: Custom Output
references: Craig J.R. and the Raven Development Team Raven user's ...
model_id: HBVEC
Raven_version: 4.12
RavenPy_version: 0.21.0[24]:
snow["CumulSum_SNOW"].isel(unit_id=0).plot()
[24]:
[<matplotlib.lines.Line2D at 0x7fcd42629fd0>]
A few important notes regarding the use of :CustomOutput in xHydro:
Due to the very high modularity of these outputs, there is currently no standardization of the variable names or their units.
Furthermore, some of these variables are cumulative, while others are not, and there is currently no way to automatically identify them. It is thus the user’s responsibility to ensure that the variables are properly interpreted.
In an effort to standardize the outputs across different models, the following aggregation levels have been defined. These are noted in a
aggregation_levelattribute in the variable’s metadata, and can be used to identify the spatial resolution of the output:ComputationalUnit: In Raven, this corresponds to the Hydrological Response Units (HRUs).Subbasin: Following the Raven convention, this corresponds to the immediate drainage area of a river segment, excluding the upstream drainage area.DrainageArea: This corresponds to the cumulative drainage area of a river segment.
The CustomOutput command allows a control on the spatial resolution of the output (BY_HRU, BY_SUBBASIN, BY_DRAINAGE_AREA), but a aggregate_outputs function has additionally been implemented in xHydro to allow the aggregation of outputs in post-processing, if needed. Note that this function relies on multiple watershed properties which are deduced from the provided HRU shapefile and will fail if the HRU characteristics do not follow the BasinMaker structure and
nomenclature.
[25]:
help(hm.aggregate_outputs)
Help on method aggregate_outputs in module xhydro.modelling._ravenpy_models:
aggregate_outputs(
by: Literal['hru', 'unit', 'subbasin'],
to: Literal['subbasin', 'drainage_area'],
subset: list[str] | None = None,
**kwargs
) -> None method of xhydro.modelling._ravenpy_models.RavenpyModel instance
Aggregate the model outputs to a different spatial unit. See the Notes section for more details.
Parameters
----------
by : {"hru", "unit", "subbasin"}
The spatial unit to aggregate from.
"unit" is the generic term for "hru".
to : {"subbasin", "drainage_area"}
The spatial unit to aggregate to.
subset : list[str] | None
The list of variables to aggregate. If None, all variables will be processed.
The strings should match the names produced by the Raven model, typically found under ":CustomOutput" in the .rvi file.
\*\*kwargs : dict
Keyword arguments to pass to :py:func:`xarray.open_dataset`.
Returns
-------
None
The aggregated outputs will be saved as new NetCDF files in the output directory, with a name pattern
following what is produced by the Raven model (e.g. "{run_name}_variable}_By{aggregation}.nc").
Aggregation will be 'ByHRU', 'BySubbasin', or 'ByDrainageArea', depending on the 'to' parameter.
If a file with the same name already exists, a new file will be saved with a "_v{n}" suffix.
Notes
-----
This method expects that relevant spatial information has been provided to the RavenPy model, either through the initial configuration or
through the `update_data` method. Furthermore, that spatial information should be consistent with ravenpy.extractors.BasinMakerExtractor
expectations, as well as the Data Specifications of Basin Maker (https://hydrology.uwaterloo.ca/basinmaker/) and the outputs of
BasinMaker's `Generate_HRUs` function. In particular, the following variables should be present in the HRU file:
- Always:
- SubId: The ID of the subbasins.
- BasArea: The area of the subbasins.
- by == "hru":
- HRU_ID: The ID of the HRUs.
- HRU_Area: The area of the HRUs, in units consistent with the area of the subbasins.
- to == "drainage_area":
- DowSubId: The ID of the downstream subbasin for each HRU.
[26]:
hm.aggregate_outputs(by="hru", to="drainage_area")
[27]:
snow_agg = hm.get_outputs("SNOW*Drainage*")
snow_agg
[27]:
<xarray.Dataset> Size: 142kB
Dimensions: (time: 363, subbasin_id: 47)
Coordinates:
* time (time) datetime64[ns] 3kB 2010-01-03 ... 2010-12-31
* subbasin_id (subbasin_id) <U2 376B '3' '4' '5' '6' ... '47' '48' '49'
dowsub_id (subbasin_id) <U2 376B dask.array<chunksize=(47,), meta=np.ndarray>
station_id (subbasin_id) <U6 1kB dask.array<chunksize=(47,), meta=np.ndarray>
drainage_area (subbasin_id) float64 376B dask.array<chunksize=(47,), meta=np.ndarray>
Data variables:
CumulSum_SNOW (time, subbasin_id) float64 136kB dask.array<chunksize=(363, 47), meta=np.ndarray>
Attributes:
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-06-29T16:07:34 by Raven 4.12
description: Custom Output
references: Craig J.R. and the Raven Development Team Raven user's ...
model_id: HBVEC
Raven_version: 4.12
RavenPy_version: 0.21.03.5. Model Calibration¶
Calibrating distributed models is not yet supported by xHydro if multiple hydrometric stations are used. Users are encouraged to use the RavenPy library directly for this purpose. For single-station calibration, xHydro can be used. Refer to the lumped RavenPy documentation for more details.