9. Entrées pour la crue maximale probable (CMP)¶
9.1. Précipitation maximale probable (PMP)¶
La Précipitation Maximale Probable (PMP) est la quantité théorique maximale de précipitations qui pourrait se produire à un endroit spécifique dans un laps de temps donné, en tenant compte des conditions météorologiques les plus extrêmes. La PMP est un paramètre critique en hydrologie, en particulier pour la conception d’infrastructures telles que les barrages, réservoirs et systèmes de drainage.
Il existe plusieurs méthodes pour calculer la PMP, chacune variant en complexité et en fonction du type de données utilisées. La méthode actuellement implémentée dans xHydro est basée sur l’approche décrite par Clavet-Gaumont et al. (2017). Cette méthode consiste à maximiser l’eau précipitable sur un emplacement donné, ce qui fait référence à la quantité totale de vapeur d’eau dans l’atmosphère qui pourrait être potentiellement convertie en précipitations dans des conditions idéales. En maximisant cette valeur, la méthode estime la précipitation maximale qui pourrait théoriquement se produire à cet endroit.
[1]:
from pathlib import Path
import hvplot.xarray
import matplotlib.pyplot as plt
import numpy as np
import pooch
import xarray as xr
import xclim
import xhydro as xh
from xhydro.testing.helpers import deveraux
ERROR 1: PROJ: proj_create_from_database: Open of /home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/share/proj failed
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/xhydro/__init__.py:21: UserWarning: The `exactextract` library is not present in the environment and will not be used.
9.1.1. Acquisition des données¶
L’acquisition des données climatiques est hors de la portée de xHydro. Cependant, quelques exemples de comment obtenir et gérer de telles données sont fournis dans les Notebooks Opérations SIG et Exemple de cas d’application. Pour ce Notebook, nous allons utiliser un jeu de données test composé de 2 ans et de 9 points de grille issus des données du modèle climatique CanESM5. Dans une application réelle, il serait préférable d’avoir autant d’années de données que possible.
Pour effectuer l’analyse, certaines variables climatiques sont nécessaires.
Variables au pas de temps quotidien:
pr→ Flux de précipitationssnw→ Équivalent en eau de neigehus→ Humidité spécifique pour plusieurs niveaux de pressionzg→ Hauteur géopotentielle pour plusieurs niveaux de pression
Variables de champ fixe:
orog→ Altitude de la surface
Dans les régions froides, il peut être nécessaire de diviser les précipitations totales en composantes de pluie et de neige. De nombreux modèles climatiques fournissent déjà ces données séparément. Cependant, si ces données ne sont pas directement disponibles, des librairies comme xclim peuvent approximer la division en utilisant les données de précipitations et de température.
[2]:
from pathlib import Path
import xhydro as xh
path_day_zip = deveraux().fetch(
"pmp/CMIP.CCCma.CanESM5.historical.r1i1p1f1.day.gn.zarr.zip",
pooch.Unzip(),
)
ds_day = xr.open_zarr(Path(path_day_zip[0]).parents[0])
path_fx_zip = deveraux().fetch(
"pmp/CMIP.CCCma.CanESM5.historical.r1i1p1f1.fx.gn.zarr.zip",
pooch.Unzip(),
)
ds_fx = xr.open_zarr(Path(path_fx_zip[0]).parents[0])
# There are a few issues with attributes in this dataset that we need to address
ds_day["pr"].attrs = {"units": "mm", "long_name": "precipitation"}
ds_day["prsn"].attrs = {"units": "mm", "long_name": "snowfall"}
ds_day["rf"].attrs = {"units": "mm", "long_name": "rainfall"}
# Combine both datasets
ds = ds_day.convert_calendar("standard")
ds["orog"] = ds_fx["orog"]
ds
[2]:
<xarray.Dataset> Size: 643kB
Dimensions: (time: 730, plev: 8, y: 3, x: 3)
Coordinates:
* time (time) datetime64[ns] 6kB 2010-01-01T12:00:00 ... 2011-12-31...
* plev (plev) float64 64B 1e+05 8.5e+04 7e+04 ... 1e+04 5e+03 1e+03
* y (y) float64 24B 43.25 46.04 48.84
* x (x) float64 24B 281.2 284.1 286.9
height float64 8B ...
Data variables:
hus (time, plev, y, x) float32 210kB dask.array<chunksize=(214, 8, 3, 3), meta=np.ndarray>
lat_bounds (y) float64 24B dask.array<chunksize=(3,), meta=np.ndarray>
lon_bounds (x) float64 24B dask.array<chunksize=(3,), meta=np.ndarray>
pr (time, y, x) float64 53kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
prsn (time, y, x) float64 53kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
rf (time, y, x) float64 53kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
snw (time, y, x) float32 26kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
tas (time, y, x) float32 26kB dask.array<chunksize=(730, 3, 3), meta=np.ndarray>
time_bounds (time) object 6kB dask.array<chunksize=(730,), meta=np.ndarray>
zg (time, plev, y, x) float32 210kB dask.array<chunksize=(239, 8, 3, 3), meta=np.ndarray>
orog (y, x) float32 36B dask.array<chunksize=(3, 3), meta=np.ndarray>
Attributes: (12/56)
CCCma_model_hash: 3dedf95315d603326fde4f5340dc0519d80d10c0
CCCma_parent_runid: rc3-pictrl
CCCma_pycmor_hash: 33c30511acc319a98240633965a04ca99c26427e
CCCma_runid: rc3.1-his01
Conventions: CF-1.7 CMIP-6.2
YMDH_branch_time_in_child: 1850:01:01:00
... ...
title: CanESM5 output prepared for CMIP6
tracking_id: hdl:21.14100/d0a84c86-7fb1-4de4-8837-574504c...
variable_id: hus
variant_label: r1i1p1f1
version: v20190429
version_id: v201904299.1.2. Calcul de la PMP¶
La méthode décrite par Clavet-Gaumont et al. (2017) suit ces étapes :
- Identification des grands événements de précipitation:La première étape consiste à identifier les grands événements de précipitation qui seront maximisés. Cela se fait en filtrant les événements en fonction d’un seuil spécifié.
- Calcul de l’eau précipitable mensuelle de récurrence 100 ans:L’étape suivante consiste à calculer l’eau précipitable de récurrence 100 ans sur une base mensuelle en utilisant la distribution des Valeurs Extrêmes Généralisées (GEV), avec un plafond maximum de 20 % supérieur à la valeur observée la plus grande.
- Maximisation des précipitations lors des événements:À cette étape, les événements de précipitation sont maximisés en fonction du rapport entre l’eau précipitable mensuelle de récurrence 100 ans et l’eau précipitable lors des principaux événements de précipitation. Dans les régions sans neige, c’est le résultat final.
- Séparation saisonnière dans les régions froides:Dans les régions froides, les résultats sont séparés en saisons (par exemple, printemps, été) pour tenir compte de la neige lors du calcul des Crues Maximales Probables (CMP).
Cette méthode fournit une approche complète pour estimer la PMP, en tenant compte à la fois des variations de température et de précipitations à travers différentes régions et saisons.
9.1.3. Grands événements de précipitation¶
La première étape pour calculer la Précipitation Maximale Probable (PMP) consiste à filtrer les données de précipitation pour ne retenir que les événements qui dépassent un certain seuil. Ces grands événements de précipitation seront maximisés dans les étapes suivantes. La fonction xh.indicators.pmp.major_precipitation_events peut être utilisée à cette fin. Elle offre également l’option de sommer les précipitations sur un nombre spécifié de jours, ce qui peut aider à agréger les événements de tempête. Pour les données 2D, comme dans cet exemple, chaque point de grille est traité indépendamment.
Dans cet exemple, nous allons filtrer les 10 % des tempêtes les plus intenses pour éviter de surévaluer les événements de précipitation plus petits pendant le processus de maximisation. De plus, nous nous concentrerons sur les précipitations liquides (rf) plutôt que sur les précipitations totales (pr) afin d’exclure les tempêtes de neige.
[3]:
Help on function major_precipitation_events in module xhydro.indicators.pmp:
major_precipitation_events(
da: xr.DataArray,
*,
windows: list[int],
quantile: float | None = None,
min_prec: str = '0 mm'
)
Get precipitation events that exceed a given quantile for a given time step accumulation. Based on Clavet-Gaumont et al. (2017).
Parameters
----------
da : xr.DataArray
DataArray containing the precipitation values.
windows : list of int
List of the number of time steps to accumulate precipitation.
quantile : float, optional
Threshold that limits the events to those that exceed this quantile.
If `quantile` is None, the function returns all the accumulated values.
min_prec : Quantified
Minimum precipitation value to consider an event.
Values equal to `min_prec` are excluded. Defaults to 0 mm.
Returns
-------
xr.DataArray
Masked DataArray containing the major precipitation events.
Notes
-----
https://doi.org/10.1016/j.ejrh.2017.07.003
[4]:
precipitation_events = xh.indicators.pmp.major_precipitation_events(
ds.rf, windows=[1], quantile=0.9, min_prec="0.1 mm"
)
ds.rf.isel(x=1, y=1).hvplot() * precipitation_events.isel(
x=1, y=1, window=0
).hvplot.scatter(color="red")
[4]:
9.1.4. Eau précipitable quotidienne¶
AVERTISSEMENT
Cette étape doit être évitée si possible, car elle consiste à approximer l’eau précipitable à partir de l’intégrale de l’humidité spécifique et sera fortement sensible au nombre de niveaux de pression utilisés. Si disponible, les utilisateurs sont fortement encouragés à utiliser une variable ou une combinaison de variables qui représentent directement l’eau précipitable.
L’eau précipitable peut être estimée en utilisant xhydro.indicators.pmp.precipitable_water pour intégrer la colonne verticale de l’humidité. Ce processus nécessite des données d’humidité spécifique, de hauteur géopotentielle et d’altitude. La valeur résultante représente la quantité totale de vapeur d’eau qui pourrait être précipitée de l’atmosphère sous des conditions idéales.
[5]:
Help on function precipitable_water in module xhydro.indicators.pmp:
precipitable_water(
*,
hus: xr.DataArray,
zg: xr.DataArray,
orog: xr.DataArray,
windows: list[int] | None = None,
beta_func: bool = True,
add_pre_lay: bool = False
)
Compute precipitable water based on Clavet-Gaumont et al. (2017) and Rousseau et al (2014).
Parameters
----------
hus : xr.DataArray
Specific humidity. Must have a pressure level (plev) dimension.
zg : xr.DataArray
Geopotential height. Must have a pressure level (plev) dimension.
orog : xr.DataArray
Surface altitude.
windows : list of int, optional
Duration of the event in time steps. Defaults to [1].
Note that an additional time step will be added to the window size to account for antecedent conditions.
beta_func : bool, optional
If True, use the beta function proposed by Boer (1982) to get the pressure layers above the topography.
If False, the surface altitude is used as the lower boundary of the atmosphere assuming that the surface altitude
and the geopotential height are virtually identical at low altitudes.
add_pre_lay : bool, optional
If True, add the pressure layer between the surface and the lowest pressure level (e.g., at sea level).
If False, only the pressure layers between the lowest and highest pressure level are considered.
Returns
-------
xr.DataArray
Precipitable water.
Notes
-----
1) The precipitable water of an event is defined as the maximum precipitable water found during the entire duration of the event,
extending up to one time step before the start of the event. Thus, the rolling operation made using `windows` is a maximum, not a sum.
2) beta_func = True and add_pre_lay = False follow Clavet-Gaumont et al. (2017) and Rousseau et al (2014).
3) https://doi.org/10.1016/j.ejrh.2017.07.003
https://doi.org/10.1016/j.jhydrol.2014.10.053
https://doi.org/10.1175/1520-0493(1982)110<1801:DEIIC>2.0.CO;2
[6]:
pw = xh.indicators.pmp.precipitable_water(
hus=ds.hus,
zg=ds.zg,
orog=ds.orog,
windows=[1],
add_pre_lay=False,
)
pw.isel(x=1, y=1, window=0).hvplot()
[6]:
9.1.5. Eau précipitable mensuelle de récurrence 100 ans¶
Selon Clavet-Gaumont et al. (2017), l’eau précipitable mensuelle de récurrence 100 ans doit être calculée en utilisant la distribution des Valeurs Extrêmes Généralisées (GEV). La valeur doit être limitée à un maximum de 20 % supérieur à la valeur maximale observée de l’eau précipitable pour un mois donné. Cette approche garantit que l’événement estimé sur 100 ans est réaliste et contraint par les données observées.
Pour calculer cela, vous pouvez utiliser la fonction xh.indicators.pmp.precipitable_water_100y. Si vous utilisez rebuild_time, la sortie aura le même axe temporel que les données d’origine.
[7]:
Help on function precipitable_water_100y in module xhydro.indicators.pmp:
precipitable_water_100y(
pw: xr.DataArray,
*,
dist: str,
method: str,
mf: float | None = None,
n: int | None = None,
rebuild_time: bool = True
)
Compute the 100-year return period of precipitable water for each month. Based on Clavet-Gaumont et al. (2017).
Parameters
----------
pw : xr.DataArray
DataArray containing the precipitable water.
dist : str
Probability distributions.
method : {"ML" or "MLE", "MM", "PWM", "APP"}
Fitting method, either maximum likelihood (ML or MLE), method of moments (MM) or approximate method (APP).
Can also be the probability weighted moments (PWM), also called L-Moments, if a compatible `dist` object is passed.
mf : float, optional
Maximum majoration factor of the 100-year event compared to the maximum of the timeseries.
Used as an upper limit for the frequency analysis.
n : int, optional
Minimum number of data points for each month required to fit the statistical distribution.
If a given month contains fewer data points than this value, `pw100` is set to the maximum value of `pw` for that month.
rebuild_time : bool
Whether or not to reconstruct a timeseries with the same time dimensions as `pw`.
Returns
-------
xr.DataArray
Precipitable water for a 100-year return period.
Notes
-----
https://doi.org/10.1016/j.ejrh.2017.07.003
[8]:
pw100 = xh.indicators.pmp.precipitable_water_100y(
pw.sel(window=1).chunk(dict(time=-1)),
dist="genextreme",
method="ML",
mf=0.2,
rebuild_time=True,
).compute()
pw.isel(x=1, y=1, window=0).hvplot() * pw100.isel(x=1, y=1).hvplot()
[8]:
[9]:
x = np.array([2, 5, 6, 7, 7])
y = [5, 7]
np.isin(x, y)
[9]:
array([False, True, False, True, True])
9.1.6. Précipitations maximisées¶
INFO
Cette étape suit la méthodologie décrite dans Clavet-Gaumont et al., 2017. Elle est appelée « Maximisation des précipitations », cependant, elle applique effectivement un rapport basé sur l’eau précipitable mensuelle de récurrence 100 ans. Si un événement historique a dépassé cette valeur—comme cela a été observé pour janvier 2011—le résultat peut en réalité réduire les précipitations, plutôt que de les augmenter.
Avec les informations recueillies jusqu’à présent, nous pouvons procéder à la maximisation des événements de précipitation. Bien que xhydro ne fournisse pas de fonction explicite pour cette étape, elle peut être accomplie en suivant ces étapes:
Calculer le rapport: Premièrement, calculez le rapport entre l’eau précipitable mensuelle de récurrence 100 ans et l’eau précipitable lors des principaux événements de précipitation.
Appliquer le rapport : Ensuite, appliquez ce rapport aux valeurs de précipitations elles-mêmes pour maximiser les événements de précipitation en conséquence.
Ce processus ajuste les événements de précipitation en fonction de l’eau précipitable de récurrence 100 ans, fournissant une estimation des précipitations maximales possibles.
[10]:
# Precipitable water on the day of the major precipitation events.
pw_events = pw.where(precipitation_events > 0)
ratio = pw100 / pw_events
# Apply the ratio onto precipitation itself
precipitation_max = ratio * precipitation_events
precipitation_max.name = "maximized_precipitation"
ds.rf.isel(x=1, y=1).hvplot() * precipitation_max.isel(
x=1, y=1, window=0
).hvplot.scatter(color="red")
[10]:
9.1.7. Masque saisonnier¶
Dans les régions froides, le calcul des Crues Maximales Probables (CMP) implique souvent des scénarios qui combinent à la fois les précipitations et le manteau neigeux. Par conséquent, les valeurs de PMP peuvent devoir être séparées en deux catégories : pluie-sur-neige (c’est-à-dire, « printemps ») et précipitations sans neige (c’est-à-dire, « été »).
Cela peut être facilement calculé en utilisant xhydro.indicators.pmp.compute_spring_and_summer_mask, qui définit les dates de début et de fin du printemps, de l’été et de l’hiver en fonction de la présence de neige au sol, selon les critères suivants :
Hiver :
Début de l’hiver : Le premier jour après lequel il y a au moins 14 jours consécutifs avec de la neige au sol.
Fin de l’hiver : Le dernier jour avec de la neige au sol, suivi d’au moins 45 jours consécutifs sans neige.
Printemps :
Début du printemps : 60 jours avant la fin de l’hiver.
Fin du printemps : 30 jours après la fin de l’hiver.
Été :
La période estivale est définie comme la période entre les hivers. Cette période n’est pas influencée par le fait qu’elle tombe pendant l’été ou l’automne traditionnels, mais marque simplement l’intervalle entre les saisons de neige.
[11]:
Help on function compute_spring_and_summer_mask in module xhydro.indicators.pmp:
compute_spring_and_summer_mask(
snw: xr.DataArray,
*,
thresh: str = '1 cm',
window_wint_start: int = 14,
window_wint_end: int = 45,
spr_start: int = 60,
spr_end: int = 30,
freq: str = 'YS-JUL'
)
Create a mask that defines the spring and summer seasons based on the snow water equivalent.
Parameters
----------
snw : xarray.DataArray
Snow water equivalent. Must be a length (e.g. "mm") or a mass (e.g. "kg m-2").
thresh : Quantified
Threshold snow thickness to define the start and end of winter.
window_wint_start : int
Minimum number of days with snow depth above or equal to threshold to define the start of winter.
window_wint_end : int
Maximum number of days with snow depth below or equal to threshold to define the end of winter.
spr_start : int
Number of days before the end of winter to define the start of spring.
spr_end : int
Number of days after the end of winter to define the end of spring.
freq : str
Frequency of the time axis (annual frequency). Defaults to "YS-JUL".
Returns
-------
xr.Dataset
Dataset with two DataArrays (mask_spring and mask_summer), with values of 1 where the
spring and summer criteria are met and 0 where they are not.
[12]:
mask = xh.indicators.pmp.compute_spring_and_summer_mask(
ds.snw,
thresh="1 cm",
window_wint_end=14, # Since the dataset used does not have a lot of snow, we need to be more lenient
freq="YS-SEP",
)
mask
[12]:
<xarray.Dataset> Size: 111kB
Dimensions: (time: 730, x: 3, y: 3)
Coordinates:
* time (time) datetime64[ns] 6kB 2010-01-01T12:00:00 ... 2011-12-31...
* x (x) float64 24B 281.2 284.1 286.9
* y (y) float64 24B 43.25 46.04 48.84
height float64 8B 2.0
Data variables:
mask_spring (time, y, x) float64 53kB dask.array<chunksize=(365, 3, 3), meta=np.ndarray>
mask_summer (time, y, x) float64 53kB dask.array<chunksize=(365, 3, 3), meta=np.ndarray>[13]:
xclim.core.units.convert_units_to(
ds.isel(x=1, y=1).snw, "cm", context="hydro"
).hvplot() * (mask.mask_spring.isel(x=1, y=1) * 10).hvplot() * (
mask.mask_summer.isel(x=1, y=1) * 8
).hvplot()
[13]:
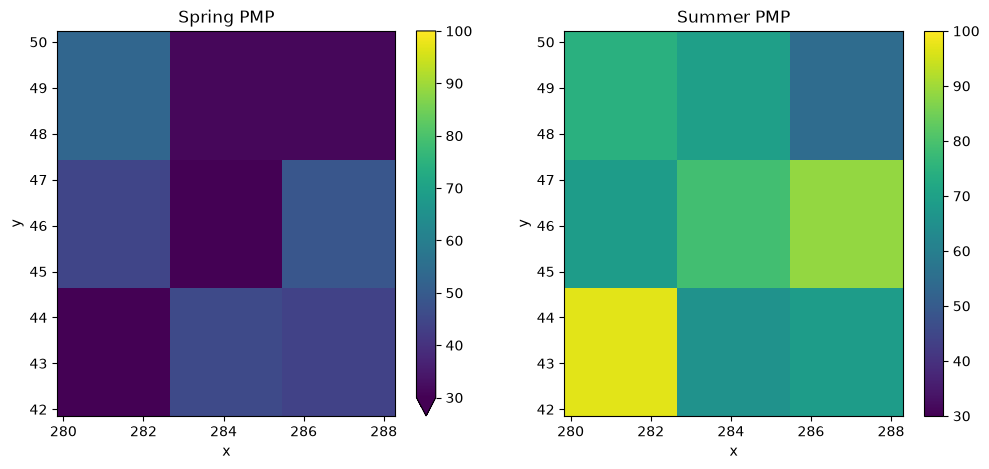
9.1.8. PMP finale¶
La PMP finale est obtenue en trouvant la valeur maximale sur la dimension time. Dans notre cas, puisque nous avons calculé un masque saisonnier, nous pouvons affiner les résultats en une PMP pour le printemps et l’été.
[14]:
pmp_spring = (precipitation_max * mask.mask_spring).max("time").compute()
pmp_summer = (precipitation_max * mask.mask_summer).max("time").compute()
[15]:
plt.subplots(1, 2, figsize=[12, 5])
ax = plt.subplot(1, 2, 1)
pmp_spring.sel(window=1).plot(vmin=30, vmax=100)
plt.title("Spring PMP")
ax = plt.subplot(1, 2, 2)
pmp_summer.sel(window=1).plot(vmin=30, vmax=100)
plt.title("Summer PMP")
[15]:
Text(0.5, 1.0, 'Summer PMP')
9.1.9. PMP avec configurations de tempêtes agrégées¶
Dans certains cas, il peut être préférable d’éviter de traiter chaque point de grille indépendamment. À la place, les tempêtes peuvent être agrégées en utilisant différentes configurations pour fournir une estimation plus représentative à l’échelle régionale. Ces configurations permettent une moyenne spatiale des événements de tempête, ce qui peut aider à réduire la variabilité entre les points de grille et fournir des résultats plus fiables.
Différentes configurations d’agrégation sont discutées dans Clavet-Gaumont et al. (2017) et ont été implémentées dans xHydro sous la fonction xhydro.indicators.pmp.spatial_average_storm_configurations.
Notez que l’eau précipitable doit d’abord être calculée de manière distribuée puis moyennée spatialement pour obtenir l’eau précipitable agrégée.
Help on function spatial_average_storm_configurations in module xhydro.indicators.pmp:
spatial_average_storm_configurations(da, *, radius)
Compute the spatial average for different storm configurations proposed by Clavet-Gaumont et al. (2017).
Parameters
----------
da : xr.DataArray
DataArray containing the precipitation values.
radius : float
Maximum radius of the storm.
Returns
-------
xr.DataSet
DataSet containing the spatial averages for all the storm configurations. The y and x coordinates indicate
the location of the storm. This location is determined by n//2, where n is the total number of cells for
both the rows and columns in the configuration, and // represents floor division.
Notes
-----
https://doi.org/10.1016/j.ejrh.2017.07.003.
[17]:
ds_agg = []
for variable in ["rf", "pw", "snw"]:
if variable == "pw":
ds_agg.extend(
[xh.indicators.pmp.spatial_average_storm_configurations(pw, radius=3)]
)
else:
ds_agg.extend(
[
xh.indicators.pmp.spatial_average_storm_configurations(
ds[variable], radius=3
)
]
)
ds_agg = xr.merge(ds_agg).chunk(dict(time=-1))
# The aggreagtion creates NaN values for snow, so we'll restrict the domain
ds_agg = ds_agg.isel(y=slice(0, -1), x=slice(0, -1))
ds_agg
/tmp/ipykernel_5671/1017207950.py:15: FutureWarning: In a future version of xarray the default value for compat will change from compat='no_conflicts' to compat='override'. This is likely to lead to different results when combining overlapping variables with the same name. To opt in to new defaults and get rid of these warnings now use `set_options(use_new_combine_kwarg_defaults=True) or set compat explicitly.
[17]:
<xarray.Dataset> Size: 497kB
Dimensions: (conf: 7, y: 2, x: 2, time: 730, window: 1)
Coordinates:
* conf (conf) object 56B '2.1' '2.2' '3.1' ... '3.4' '4.1'
* y (y) float64 16B 43.25 46.04
* x (x) float64 16B 281.2 284.1
* time (time) datetime64[ns] 6kB 2010-01-01T12:00:00 ... 201...
* window (window) int64 8B 1
height float64 8B 2.0
Data variables:
rf (conf, time, y, x) float64 164kB dask.array<chunksize=(1, 730, 1, 1), meta=np.ndarray>
precipitable_water (conf, window, time, y, x) float64 164kB dask.array<chunksize=(1, 1, 730, 1, 1), meta=np.ndarray>
snw (conf, time, y, x) float64 164kB dask.array<chunksize=(1, 730, 1, 1), meta=np.ndarray>
Attributes:
units: mmAprès avoir appliqué l’agrégation des tempêtes, les étapes suivantes restent les mêmes qu’auparavant, suivant le processus standard de calcul da le PMP.
[18]:
pe_agg = xh.indicators.pmp.major_precipitation_events(
ds_agg.rf, windows=[1], quantile=0.9, min_prec="0.1 mm"
)
pw100_agg = xh.indicators.pmp.precipitable_water_100y(
ds_agg.sel(window=1).precipitable_water, dist="genextreme", method="ML", mf=0.2
)
# Maximization
pw_events_agg = ds_agg.precipitable_water.where(pe_agg > 0)
r_agg = pw100_agg / pw_events_agg
pmax_agg = r_agg * pe_agg
# Season mask
mask_agg = xh.indicators.pmp.compute_spring_and_summer_mask(
ds_agg.snw,
thresh="1 cm",
window_wint_start=14,
window_wint_end=14,
spr_start=60,
spr_end=30,
freq="YS-SEP",
)
pmp_spring_agg = pmax_agg * mask_agg.mask_spring
pmp_summer_agg = pmax_agg * mask_agg.mask_summer
pmp_summer_agg
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/array/core.py:5201: PerformanceWarning: Increasing number of chunks by factor of 28
[18]:
<xarray.DataArray (conf: 7, y: 2, x: 2, time: 730, window: 1)> Size: 164kB
dask.array<mul, shape=(7, 2, 2, 730, 1), dtype=float64, chunksize=(1, 1, 1, 365, 1), chunktype=numpy.ndarray>
Coordinates:
* conf (conf) object 56B '2.1' '2.2' '3.1' '3.2' '3.3' '3.4' '4.1'
* y (y) float64 16B 43.25 46.04
* x (x) float64 16B 281.2 284.1
* time (time) datetime64[ns] 6kB 2010-01-01T12:00:00 ... 2011-12-31T12...
* window (window) int64 8B 1
height float64 8B 2.0
quantile float64 8B 0.9Auparavant, la PMP finale pour chaque saison était obtenue en prenant la valeur maximale sur la dimension time. Dans cette approche mise à jour, nous pouvons désormais prendre la valeur maximale à la fois sur les dimensions time et conf, en utilisant nos multiples configurations de tempêtes.
[19]:
# Final results
pmp_spring_agg = pmp_spring_agg.max(dim=["time", "conf"])
pmp_summer_agg = pmp_summer_agg.max(dim=["time", "conf"])
pmp_summer_agg
[19]:
<xarray.DataArray (y: 2, x: 2, window: 1)> Size: 32B
dask.array<_nanmax_skip-aggregate, shape=(2, 2, 1), dtype=float64, chunksize=(1, 1, 1), chunktype=numpy.ndarray>
Coordinates:
* y (y) float64 16B 43.25 46.04
* x (x) float64 16B 281.2 284.1
* window (window) int64 8B 1
height float64 8B 2.0
quantile float64 8B 0.9[20]:
# Compare results for the central grid cell
print(
f"Grid-cell summer PMP: {np.round(pmp_summer.isel(x=1, y=1, window=0).values, 1)} mm"
)
print(
f"Aggregated summer PMP: {np.round(pmp_summer_agg.isel(x=1, y=1, window=0).values, 1)} mm"
)
Grid-cell summer PMP: 78.7 mm
Aggregated summer PMP: 67.7 mm
9.2. Accumulation de neige maximale probable (ANMP)¶
L’ANMP représente l’équivalent en eau de neige (ÉEN) maximal théorique pouvant s’accumuler en une année dans les conditions météorologiques les plus extrêmes. La méthode actuellement implémentée dans xHydro suit l’approche présentée par Klein et al. (2016). Dans cette étude, les auteurs ont développé une technique d’estimation de l’ANMP à partir de données simulées issues de modèles climatiques régionaux, dans le but de maximiser l’eau précipitable associée aux chutes de neige.
La méthode décrite par Klein et al. (2016) suit les étapes suivantes :
- Identification de l’eau précipitable menant à des chutes de neige :Les données d’eau précipitable sont filtrées à l’aide de seuils définis pour la pluie et la neige, afin d’isoler les valeurs associées aux événements neigeux.
- Calcul de l’eau précipitable mensuelle centennale associée à la neige :Les valeurs mensuelles centennales d’eau précipitable associées aux chutes de neige sont estimées à l’aide de la distribution Gamma.
- Maximisation des événements de chutes de neige :Les événements de chutes de neige sont maximisés en fonction du ratio entre l’eau précipitable mensuelle centennale entraînant des chutes de neige et l’eau précipitable observée lors de ces événements.
- Estimation de l’ANMP :Pour chaque hiver, les événements de neige maximisés et non maximisés sont agrégés. L’ANMP est ensuite définie comme le total le plus élevé parmi tous les hivers.
9.2.1. Identification de l’eau précipitable conduisant à des chutes de neige¶
Klein et al. (2016) ont proposé de ne considérer que les valeurs d’eau précipitable correspondant à des pas de temps présentant au moins 0,25 mm/6h de précipitations solides (exprimées en équivalent en eau) et moins de 0,1 mm/6h de pluie. Étant donné que dans cet exemple nous utilisons des pas de temps quotidiens, ces seuils ont été ajustés à 1 mm/jour et 0,4 mm/jour, respectivement.
[21]:
prsn_threshold = "1 mm"
prra_threshold = "0.4 mm"
Dans certains cas, des chutes de neige et des précipitations ont lieu au cours du même pas de temps. Cependant, il n’est généralement pas possible de les distinguer. Pour éviter d’inclure des valeurs d’eau précipitable associées aux événements pluvieux, les auteurs ont proposé les trois méthodes suivantes :
m1 : Seuls les événements de neige non accompagnés de pluie sont pris en compte pour la maximisation. Pour l’eau précipitable correspondant à un événement donné, on ne considère que les pas de temps présentant au moins la quantité minimale de neige et moins que la quantité minimale de pluie.
m2 : Les événements de neige dépassant le seuil établi pour la maximisation (c’est-à-dire la quantité minimale de neige) sont maximisés, qu’ils soient accompagnés de pluie ou non. Pour l’eau précipitable correspondant à un événement donné, on considère uniquement les pas de temps présentant au moins la quantité minimale de neige.
m3 : Ce sont les mêmes événements que ceux sélectionnés pour m2, mais si la quantité de pluie dépasse également le seuil minimal, l’eau précipitable est multipliée par le rapport entre la neige (en mm équivalent d’eau) et les précipitations totales. Cette multiplication permet d’estimer la quantité d’eau précipitable conduisant aux chutes de neige.
Nous commençons par calculer les événements de précipitation et leurs composantes de pluie et de neige pour une accumulation donnée.
INFO
Pour simplifier l’exemple, la durée de l’événement de précipitation est fixée à un seul pas de temps (windows = [1]). Lors du calcul de l’ANMP, les utilisateurs doivent porter une attention particulière au paramètre window, car il peut influencer de manière significative les résultats. Klein et al. (2016) suggèrent d’utiliser un algorithme permettant de déterminer la durée réelle de chaque chute de neige simulée, plutôt que d’utiliser des durées prédéfinies.
[22]:
precipitation_events = xh.indicators.pmp.major_precipitation_events(ds.pr, windows=[1], min_prec="0.1 mm")
prra_events = xh.indicators.pmp.major_precipitation_events(ds.rf, windows=[1], min_prec="0.1 mm")
prsn_events = xh.indicators.pmp.major_precipitation_events(ds.prsn, windows=[1], min_prec="0.1 mm")
[23]:
pw_snowfall_m1 = xh.indicators.pmp.pw_snowfall(
pw,
method="m1",
prsn_events=prsn_events,
prsn_threshold=prsn_threshold,
prra_events=prra_events,
prra_threshold=prra_threshold,
)
pw_snowfall_m2 = xh.indicators.pmp.pw_snowfall(
pw, method="m2", prsn_events=prsn_events, prsn_threshold=prsn_threshold
)
pw_snowfall_m3 = xh.indicators.pmp.pw_snowfall(
pw,
method="m3",
prsn_events=prsn_events,
prsn_threshold=prsn_threshold,
prra_events=prra_events,
prra_threshold=prra_threshold,
pr_events=precipitation_events,
)
pw.isel(x=1, y=1, window=0).hvplot(label="pw") * pw_snowfall_m1.isel(
x=1, y=1, window=0
).hvplot.scatter(color="purple", marker="o", size=75, label="M1") * pw_snowfall_m2.isel(
x=1, y=1, window=0
).hvplot.scatter(
color="green", marker="v", size=50, label="M2"
) * pw_snowfall_m3.isel(
x=1, y=1, window=0
).hvplot.scatter(
color="red", marker="*", label="M3"
)
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: divide by zero encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: invalid value encountered in divide
[23]:
Comme suggéré par Klein et al. (2016), nous avons utilisé la méthodologie M3 dans cet exemple.
9.2.2. Calcul de l’eau précipitable mensuelle centennale menant à des chutes de neige (pw100)¶
Klein et al. (2016) recommandent d’ajuster une distribution Gamma non stationnaire. Actuellement, seule la version stationnaire est implémentée, mais une version non stationnaire est prévue pour une future mise à jour. La distribution GEV peut également être utilisée à des fins d’extrapolation. Une version non stationnaire de celle-ci est disponible dans le package xhydro.
Klein et al. (2016) suggèrent également d’utiliser l’eau précipitable maximale observée comme pw100 lorsqu’il y a moins de 20 points de données dans un mois (c’est-à-dire n = 20). De plus, conformément à leur méthodologie, pw100 n’est pas limité (c’est-à-dire mf=None). Cependant, cette hypothèse doit être examinée au cas par cas.
[24]:
pw100_snow_events_m3 = xh.indicators.pmp.precipitable_water_100y(
pw_snowfall_m3.sel(window=1).chunk(dict(time=-1)),
dist="gamma",
method="ML",
mf=None,
n=20,
rebuild_time=True,
).compute()
pw.isel(x=0, y=1, window=0).hvplot(label="pw") * pw100_snow_events_m3.isel(
x=0, y=1
).hvplot(label="pw₁₀₀") * pw_snowfall_m3.isel(x=0, y=1, window=0).hvplot.scatter(
color="red", marker="*", label="m3"
)
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: divide by zero encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: invalid value encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: divide by zero encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: invalid value encountered in divide
[24]:
9.2.3. Maximisation des événements de neige¶
Avec les informations recueillies jusqu’à présent, nous pouvons maintenant procéder à la maximisation des événements de neige. Bien que xHydro ne fournisse pas de fonction explicite pour cette étape, cela peut être accompli en suivant les étapes suivantes :
Calcul du rapport de maximisation (r) : Calculez le ratio entre l’eau précipitable mensuelle centennale menant à des chutes de neige et l’eau précipitable observée lors des événements neigeux.
Limiter le rapport (r) : Limitez le ratio à 1 ≤ r ≤ 2,5 comme suggéré par Klein et al. (2016).
Appliquer le rapport :
Klein et al. (2016) suggèrent de maximiser uniquement les événements de neige qui dépassent un seuil donné pendant une durée spécifiée. Ainsi, seuls les événements répondant à ce critère sont multipliés par le rapport de maximisation correspondant (r). Si le critère n’est pas rempli, l’événement neigeux n’est pas maximisé.
Les auteurs ont utilisé différents seuils en fonction de la durée de l’événement :
Durée de 6 heures : 3, 4, 5, 6 mm
Durée de 12 heures : 4, 5, 6, 7 mm
Durée de 24 heures : 5, 6, 7, 8 mm
Dans cet exemple, un seuil de 6 mm a été sélectionné pour la durée d’un jour.
[25]:
limit = 2.5
maximization_threshold = "6 mm"
maximization_threshold_converted = xclim.core.units.convert_units_to(
maximization_threshold, prsn_events
) # Convert thresholds to match the data's units
r = pw100_snow_events_m3 / pw_snowfall_m3
r_limited = xr.where(r > limit, limit, r)
r_limited = xr.where(r_limited < 1, 1, r_limited)
max_snow_events = xr.where(
prsn_events >= maximization_threshold_converted, r_limited * prsn_events, np.nan
)
max_snow_events.name = "max_snow_events"
non_max_snow_events = prsn_events.where(prsn_events < maximization_threshold_converted)
non_max_snow_events.name = "non_max_snow_events"
L’accumulation de neige maximisée (ANM) est la somme des événements maximisés et non maximisés tout au long d’un hiver
[26]:
snow_sum = xr.concat([non_max_snow_events, max_snow_events], dim="variable").sum(
"variable"
)
snow_sum.isel(x=1, y=1, window=0).hvplot(
label="Maximized snowfall", color="red"
) * max_snow_events.isel(x=1, y=1, window=0).hvplot.scatter(
color="red", label="Maximized events"
) * prsn_events.isel(
x=1, y=1, window=0
).hvplot(
label="Snowfall", color="#30a2da", line_dash="dashed"
)
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: divide by zero encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: invalid value encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: divide by zero encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: invalid value encountered in divide
[26]:
9.2.4. Estimation de l’ANMP¶
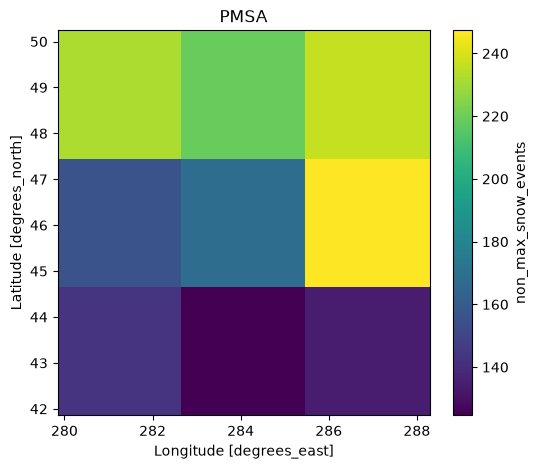
L’ANM est le total le plus élevé parmi tous les hivers définis.
[27]:
pmsa = snow_sum.resample(time="YS-JUL").sum(dim="time").max(dim="time")
pmsa
[27]:
<xarray.DataArray 'non_max_snow_events' (window: 1, y: 3, x: 3)> Size: 72B
dask.array<_nanmax_skip-aggregate, shape=(1, 3, 3), dtype=float64, chunksize=(1, 3, 3), chunktype=numpy.ndarray>
Coordinates:
* window (window) int64 8B 1
* y (y) float64 24B 43.25 46.04 48.84
* x (x) float64 24B 281.2 284.1 286.9
height float64 8B 2.0
quantile float64 8B 0.99[28]:
plt.subplots(1, 1, figsize=[6, 5])
ax = plt.subplot(1, 1, 1)
pmsa.sel(window=1).plot()
plt.title("PMSA")
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: divide by zero encountered in divide
/home/docs/checkouts/readthedocs.org/user_builds/xhydro-fr/conda/latest/lib/python3.14/site-packages/dask/_task_spec.py:768: RuntimeWarning: invalid value encountered in divide
[28]:
Text(0.5, 1.0, 'PMSA')