Exemple de cas d’utilisation¶
Cet exemple illustre un cas d’utilisation qui couvre les étapes essentielles de la construction d’un modèle hydrologique et de l’analyse de l’impact des changements climatiques :
Identification du bassin versant et de ses principales caractéristiques
Bassin versant de la rivière Beaurivage dans le sud du Québec, à l’emplacement de la station 023401.
Collecte des données observées
Données ERA5-Land et données de débit.
Préparation et calage du modèle hydrologique
GR4JCN émulé par le cadre hydrologique Raven.
Calcul des indicateurs hydrologiques
Débit moyen estival
Débit moyen mensuel
Débit maximum sur 20 et 100 ans
Débit estival minimal sur 7 jours de récurrence 2 ans
Évaluation de l’impact des changements climatiques
Simulations CMIP6 post-traitées du jeu de données ESPO-G6-R2
Identification d’un bassin versant et de ses caractéristiques¶
INFO
Pour plus d’informations sur cette section et les options disponibles, consultez le Notebook GIS.
Cette première étape dépend fortement du modèle hydrologique. Puisque nous utiliserons GR4JCN dans notre exemple, nous devons obtenir la superficie du bassin versant, les coordonnées du centroïde et l’altitude. Nous aurons également besoin de la délimitation du bassin versant pour extraire les données météorologiques. Toutes ces informations peuvent être obtenues via la fonction xhydro.gis.watershed_to_raven_hru, qui fait appel à diverses fonctions de ce module.
[1]:
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
[2]:
from IPython.display import clear_output
import xhydro.gis as xhgis
clear_output(wait=False)
[3]:
# Watershed delineation
coords = (-71.28878, 46.65692)
gdf = xhgis.watershed_to_raven_hru(coords)
gdf
[3]:
| HRU_ID | area | latitude | longitude | elevation | SubId | DowSubId | geometry | |
|---|---|---|---|---|---|---|---|---|
| 0 | 7120365812 | 585.585577 | 46.452161 | -71.260464 | 222.55365 | 1 | -1 | POLYGON ((-71.09758 46.40035, -71.09409 46.403... |
Puisque xhgis.watershed_delineation extrait le polygone HydroBASINS le plus proche, le bassin versant pourrait ne pas correspondre exactement aux coordonnées demandées. La station de jaugeage 023401 a une aire de drainage associée de 708 km², ce qui diffère de nos résultats. Le débit devra être ajusté en utilisant un facteur d’échelle.
[4]:
gauge_area = 708
scaling_factor = gdf.iloc[0]["area"] / gauge_area
scaling_factor
[4]:
np.float64(0.8270982719703007)
Collecte des données observées¶
[5]:
import geopandas as gpd
import matplotlib.pyplot as plt
import xarray as xr
# For easy access to the specific streamflow data used here
import xdatasets
import xscen
Données météorologiques¶
INFO
Plusieurs librairies peuvent être utilisées pour effectuer ces étapes. Par souci de simplicité, cet exemple utilisera les modules subset et aggregate de la librairie xscen.
Cet exemple utilisera les données journalières ERA5-Land hébergées sur la plateforme PAVICS.
[6]:
# Extraction of ERA5-Land data
meteo_ref = xr.open_dataset(
"https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/reanalyses/day_ERA5-Land_NAM.ncml",
engine="netcdf4",
chunks={"time": 365, "lon": 50, "lat": 50},
)[["pr", "tasmin", "tasmax"]]
meteo_ref
[6]:
<xarray.Dataset> Size: 454GB
Dimensions: (time: 27790, lat: 801, lon: 1700)
Coordinates:
* time (time) datetime64[ns] 222kB 1950-01-01 1950-01-02 ... 2026-01-31
* lat (lat) float32 3kB 10.0 10.1 10.2 10.3 10.4 ... 89.7 89.8 89.9 90.0
* lon (lon) float32 7kB -179.9 -179.8 -179.7 -179.6 ... -10.2 -10.1 -10.0
Data variables:
pr (time, lat, lon) float32 151GB dask.array<chunksize=(365, 50, 50), meta=np.ndarray>
tasmin (time, lat, lon) float32 151GB dask.array<chunksize=(365, 50, 50), meta=np.ndarray>
tasmax (time, lat, lon) float32 151GB dask.array<chunksize=(365, 50, 50), meta=np.ndarray>
Attributes: (12/30)
Conventions: CF-1.9
cell_methods: time: mean (interval: 1 day)
doi: https://doi.org/10.24381/cds.e2161bac
domain: NAM
frequency: day
history: [2022-12-25 09:07:39.901698] Converted variabl...
... ...
institute_id: ECMWF
dataset_id: ERA5-Land
abstract: ERA5-Land provides hourly high resolution info...
dataset_description: https://www.ecmwf.int/en/era5-land
attribution: Contains modified Copernicus Climate Change Se...
citation: Muñoz Sabater, J., (2021): ERA5-Land hourly da...Ce jeu de données couvre l’ensemble du globe et possède plus de 70 ans de données. La première étape consistera donc à sous-échantillonner les données spatialement et temporellement. Pour le sous-échantillonnage spatial, le GeoDataFrame obtenu précédemment peut être utilisé.
[7]:
meteo_ref = meteo_ref.sel(time=slice("1991", "2020")) # Temporal subsetting
meteo_ref = xscen.spatial.subset(
meteo_ref, method="shape", tile_buffer=2, shape=gdf
) # Spatial subsetting, with a buffer of 2 grid cells
meteo_ref
[7]:
<xarray.Dataset> Size: 9MB
Dimensions: (time: 10958, lat: 8, lon: 8)
Coordinates:
* time (time) datetime64[ns] 88kB 1991-01-01 1991-01-02 ... 2020-12-31
* lat (lat) float32 32B 46.1 46.2 46.3 46.4 46.5 46.6 46.7 46.8
* lon (lon) float32 32B -71.6 -71.5 -71.4 -71.3 -71.2 -71.1 -71.0 -70.9
Data variables:
pr (time, lat, lon) float32 3MB dask.array<chunksize=(355, 8, 8), meta=np.ndarray>
tasmin (time, lat, lon) float32 3MB dask.array<chunksize=(355, 8, 8), meta=np.ndarray>
tasmax (time, lat, lon) float32 3MB dask.array<chunksize=(355, 8, 8), meta=np.ndarray>
Attributes: (12/30)
Conventions: CF-1.9
cell_methods: time: mean (interval: 1 day)
doi: https://doi.org/10.24381/cds.e2161bac
domain: NAM
frequency: day
history: [2026-03-31 14:35:41] shape spatial subsetting...
... ...
institute_id: ECMWF
dataset_id: ERA5-Land
abstract: ERA5-Land provides hourly high resolution info...
dataset_description: https://www.ecmwf.int/en/era5-land
attribution: Contains modified Copernicus Climate Change Se...
citation: Muñoz Sabater, J., (2021): ERA5-Land hourly da...[8]:
ax = plt.subplot(1, 1, 1)
meteo_ref.tasmin.isel(time=0).plot(ax=ax)
gdf.plot(ax=ax)
[8]:
<Axes: title={'center': 'time = 1991-01-01'}, xlabel='longitude [degrees_east]', ylabel='latitude [degrees_north]'>
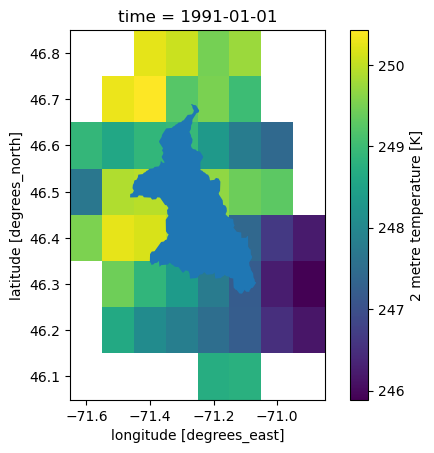
Raven attend des températures en Celsius et des précipitations en millimètres, mais elles sont actuellement dans un format conforme aux conventions CF, soient en Kelvin et en kg m⁻² s⁻¹, respectivement. La fonction xhydro.modelling.format_input peut être utilisée pour préparer les données pour la modélisation avec Raven. Elle effectue la conversion des unités, le renommage des variables et le formatage des coordonnées afin d’assurer la compatibilité avec RavenPy. Dans le cas de données météorologiques maillées—comme dans cet exemple—xHydro utilise des fonctions disponibles dans RavenPy pour attribuer des poids à chaque cellule de la grille en fonction de la portion qui chevauche le bassin versant. Alternativement, les données peuvent être agrégées manuellement avant d’être transmises au modèle.
Par souci de simplification, l’altitude de la grille sera fixée à 450 m. Le calcul de l’altitude des cellules de grille dans ERA5-Land n’est pas toujours trivial et ne fait pas partie du cadre de cet exemple.
[9]:
from pathlib import Path
import tempfile
notebook_folder = Path(tempfile.TemporaryDirectory().name)
import xhydro as xh
# Add altitude data
meteo_ref = meteo_ref.assign_coords(
{"elevation": xr.ones_like(meteo_ref.pr.isel(time=0).drop_vars("time")) * 450}
)
meteo_ref["elevation"].attrs = {"units": "m"}
meteo_ref, config_meteo_ref = xh.modelling.format_input(
meteo_ref, model="GR4JCN", save_as=notebook_folder / "_data" / "meteo.nc"
)
meteo_ref
[9]:
<xarray.Dataset> Size: 9MB
Dimensions: (time: 10958, latitude: 8, longitude: 8)
Coordinates:
* time (time) datetime64[ns] 88kB 1991-01-01 1991-01-02 ... 2020-12-31
* latitude (latitude) float32 32B 46.1 46.2 46.3 46.4 46.5 46.6 46.7 46.8
* longitude (longitude) float32 32B -71.6 -71.5 -71.4 ... -71.1 -71.0 -70.9
elevation (latitude, longitude) float32 256B dask.array<chunksize=(8, 8), meta=np.ndarray>
Data variables:
pr (time, latitude, longitude) float32 3MB dask.array<chunksize=(355, 8, 8), meta=np.ndarray>
tasmin (time, latitude, longitude) float32 3MB dask.array<chunksize=(355, 8, 8), meta=np.ndarray>
tasmax (time, latitude, longitude) float32 3MB dask.array<chunksize=(355, 8, 8), meta=np.ndarray>
Attributes: (12/30)
Conventions: CF-1.9
cell_methods: time: mean (interval: 1 day)
doi: https://doi.org/10.24381/cds.e2161bac
domain: NAM
frequency: day
history: [2026-03-31 14:35:41] shape spatial subsetting...
... ...
institute_id: ECMWF
dataset_id: ERA5-Land
abstract: ERA5-Land provides hourly high resolution info...
dataset_description: https://www.ecmwf.int/en/era5-land
attribution: Contains modified Copernicus Climate Change Se...
citation: Muñoz Sabater, J., (2021): ERA5-Land hourly da...Cette fonction retourne également de l’information qui sera utilisée plus tard pour instantier le modèle hydrologique:
[10]:
config_meteo_ref
[10]:
{'data_type': ['TEMP_MAX', 'TEMP_MIN', 'PRECIP'],
'alt_names_meteo': {'TEMP_MAX': 'tasmax',
'TEMP_MIN': 'tasmin',
'PRECIP': 'pr'},
'meteo_file': '/tmp/tmpbnxtefbc/_data/meteo.nc'}
Données hydrométriques¶
Les données de débit du gouvernement du Québec sont accessibles via la librairie xdatasets.
[11]:
qobs = (
xdatasets.Query(
**{
"datasets": {
"deh": {
"id": ["023401"],
"variables": ["streamflow"],
}
},
"time": {"start": "1991-01-01", "end": "2020-12-31"},
}
)
.data.squeeze()
.load()
).sel(spatial_agg="watershed")
[12]:
# Once again, some housekeeping is required on the metadata to make sure that xHydro understands the dataset.
qobs = qobs.rename({"streamflow": "q"})
qobs["id"].attrs["cf_role"] = "timeseries_id"
qobs = qobs.rename({"id": "station_id"})
qobs["q"].attrs = {
"long_name": "Streamflow",
"units": "m3 s-1",
"standard_name": "water_volume_transport_in_river_channel",
"cell_methods": "time: mean",
}
for c in qobs.coords:
if len(qobs[c].dims) == 0 and "time" not in c:
qobs[c] = qobs[c].expand_dims("station_id")
qobs
[12]:
<xarray.Dataset> Size: 132kB
Dimensions: (time: 10958, station_id: 1)
Coordinates: (12/15)
* time (time) datetime64[ns] 88kB 1991-01-01 ... 2020-12-31
* station_id (station_id) <U6 24B '023401'
drainage_area (station_id) float32 4B 708.0
end_date (station_id) datetime64[ns] 8B 2020-12-31
latitude (station_id) float32 4B 46.66
longitude (station_id) float32 4B -71.29
... ...
source (station_id) <U102 408B 'Ministère de l’Environnement, de ...
spatial_agg (station_id) <U9 36B 'watershed'
start_date (station_id) datetime64[ns] 8B 1991-01-01
variable (station_id) <U10 40B 'streamflow'
time_agg <U4 16B 'mean'
timestep <U1 4B 'D'
Data variables:
q (time) float32 44kB 46.0 33.9 26.2 21.0 ... 19.98 15.76 12.93[13]:
plt.figure(figsize=[10, 5])
qobs.q.plot()
[13]:
[<matplotlib.lines.Line2D at 0x7f5f93952ba0>]
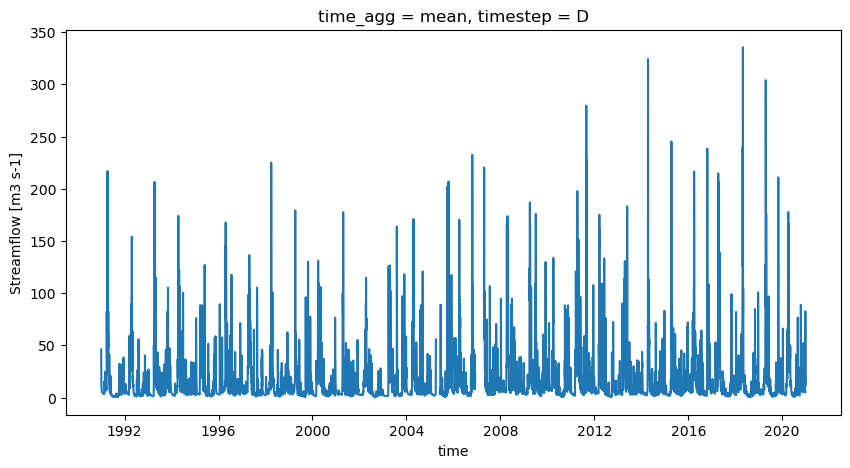
Comme spécifié plus tôt, les observations de débit doivent être modifiées pour tenir compte des différences de taille des bassins versants entre la jauge et le polygone.
[14]:
with xr.set_options(keep_attrs=True):
qobs["q"] = qobs["q"] * scaling_factor
[15]:
# Save (necessary for model calibration)
qobs.to_netcdf(notebook_folder / "_data" / "qobs.nc")
Préparation et calage du modèle hydrologique (xhydro.modelling)¶
INFO
Pour plus d’informations sur cette section et les options disponibles, consultez le Notebook de modélisation hydrologique.
[16]:
import xhydro as xh
from xhydro.modelling.calibration import perform_calibration
from xhydro.modelling.obj_funcs import get_objective_function
La fonction perform_calibration nécessite un argument model_config qui lui permet de construire le modèle hydrologique correspondant. Toutes les informations requises ont été acquises dans les sections précédentes, il ne reste plus qu’à remplir les entrées du modèle RavenPy/GR4JCN.
Pour simplifications, comme l’équivalent en eau de la neige n’est pas actuellement disponible dans la base de données sur PAVICS, « AVG_ANNUAL_SNOW » a été estimé à l’aide de Brown & Brasnett (2010).
[17]:
# Model configuration
model_config = {
"model_name": "GR4JCN",
"workdir": notebook_folder / "model",
"overwrite": True,
"parameters": [0.529, -3.396, 407.29, 1.072, 16.9, 0.947],
"hru": gdf,
"start_date": "1991-01-01",
"end_date": "2020-12-31",
"rain_snow_fraction": "RAINSNOW_DINGMAN",
"evaporation": "PET_HARGREAVES_1985",
"global_parameter": {"AVG_ANNUAL_SNOW": 100.00},
**config_meteo_ref, # Reuse information gathered earlier
}
# Parameter bounds for GR4JCN
bounds_low = [0.01, -15.0, 10.0, 0.0, 1.0, 0.0]
bounds_high = [2.5, 10.0, 700.0, 7.0, 30.0, 1.0]
[18]:
# Calibration / validation period
mask_calib = xr.where(qobs.time.dt.year <= 2010, 1, 0).values
mask_valid = xr.where(qobs.time.dt.year > 2010, 1, 0).values
# Model calibration
best_parameters, best_simulation, best_objfun = perform_calibration(
model_config,
"kge",
qobs=notebook_folder / "_data" / "qobs.nc",
bounds_low=bounds_low,
bounds_high=bounds_high,
evaluations=8,
algorithm="DDS",
mask=mask_calib,
sampler_kwargs=dict(trials=1),
)
Initializing the Dynamically Dimensioned Search (DDS) algorithm with 8 repetitions
The objective function will be maximized
Starting the DDS algorithm with 8 repetitions...
Finding best starting point for trial 1 using 5 random samples.
1 of 8, maximal objective function=0.129327, time remaining: 00:00:10
Initialize database...
['csv', 'hdf5', 'ram', 'sql', 'custom', 'noData']
2 of 8, maximal objective function=0.129327, time remaining: 00:00:11
3 of 8, maximal objective function=0.293959, time remaining: 00:00:09
4 of 8, maximal objective function=0.293959, time remaining: 00:00:08
5 of 8, maximal objective function=0.293959, time remaining: 00:00:05
6 of 8, maximal objective function=0.293959, time remaining: 00:00:03
7 of 8, maximal objective function=0.390197, time remaining: 00:00:00
8 of 8, maximal objective function=0.393656, time remaining: 23:59:57
Best solution found has obj function value of 0.3936562927318237 at 5
*** Final SPOTPY summary ***
Total Duration: 24.88 seconds
Total Repetitions: 8
Maximal objective value: 0.393656
Corresponding parameter setting:
param0: 1.13242
param1: -2.46413
param2: 43.5229
param3: 1.33209
param4: 24.153
param5: 0.0766439
******************************
Best parameter set:
param0=1.132418270728551, param1=-2.464133107201744, param2=43.522924628974806, param3=1.3320909887768697, param4=24.153016559360484, param5=0.07664389863678882
Run number 7 has the highest objectivefunction with: 0.3937
Pour réduire les temps de calcul dans cet exemple, seulement 10 étapes ont été utilisées pour la fonction de calage, ce qui est bien en dessous du nombre recommandé. Les paramètres ci-dessous ont été obtenus en exécutant le code ci-dessus avec 150 évaluations.
[19]:
# Replace the results with parameters obtained using 150 evaluations
best_parameters = [
0.3580270511815579,
-2.187141388684563,
24.012067980309702,
0.000781,
1.9330212374187332,
0.5491789347783598,
]
model_config["parameters"] = best_parameters
best_simulation = xh.modelling.hydrological_model(model_config).run()
Le vrai KGE doit être calculé à partir d’une période de validation, en utilisant get_objective_function.
[20]:
get_objective_function(
qobs=qobs.q,
qsim=best_simulation,
obj_func="kge",
mask=mask_valid,
).values
[20]:
array(0.68497379)
[21]:
ax = plt.figure(figsize=(10, 5))
qobs.q.plot(color="k", linewidth=3)
best_simulation.q.plot(color="r")
[21]:
[<matplotlib.lines.Line2D at 0x7f5f930e23c0>]
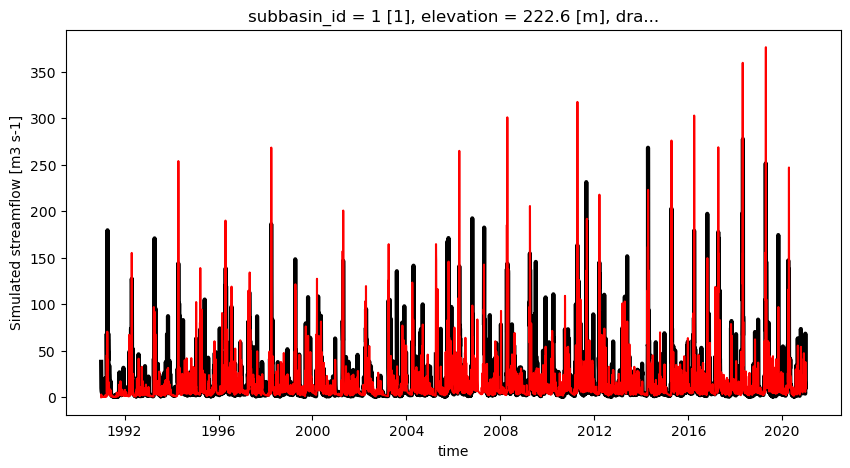
Calcul des indicateurs hydroclimatologiques¶
[22]:
import numpy as np
import xclim
import xhydro.frequency_analysis as xhfa
Indicateurs non fréquenciels¶
INFO
Pour plus d’informations sur cette section et les options disponibles, consultez le Notebook d’analyse de l’impact des changements climatiques.
INFO
Les indicateurs personnalisés dans xHydro sont construits en suivant le formatage YAML requis par xclim. »
Un indicateur personnalisé construit avec xclim.core.indicator.Indicator.from_dict nécessitera ces éléments
« data » : Un dictionnaire avec les informations suivantes :
« base » : L“« ID YAML » obtenu depuis cette page.
« input » : Un dictionnaire reliant l’entrée xclim par défaut au nom de votre variable. Nécessaire uniquement si elle diffère. Dans le lien ci-dessus, ce sont les chaînes suivant « Uses: ».
« parameters » : Un dictionnaire contenant tous les autres paramètres pour un indicateur donné. Dans le lien ci-dessus, la manière la plus simple d’y accéder est de cliquer sur le lien dans le coin supérieur droit de la boîte décrivant un indicateur donné.
Des entrées supplémentaires peuvent être utilisées ici, comme décrit dans la documentation xclim sous « identifier ».
« identifier » : Un nom personnalisé pour votre indicateur. Ce sera le nom retourné dans les résultats.
« module »: Nécessaire, mais peut être n’importe quoi. Pour éviter un écrasement accidentel des indicateurs
xclim, il est préférable d’utiliser quelque chose de différent de : [« atmos », « land », « generic »].
Pour une analyse des impacts des changements climatiques, le processus typique pour calculer les indicateurs non-fréquenciels serait de :
Définir les indicateurs soit par les fonctionnalités
xclimprésentées ci-dessous ou par un fichier YAML.Appeler
xhydro.indicators.compute_indicators, qui produira des résultats annuels par le biais d’un dictionnaire, où chaque clé représente les fréquences demandées.Appeler
xhydro.cc.climatological_oppour chaque entrée du dictionnaire afin de calculer la moyenne sur 30 ans.Recombiner les jeux de données.
Cependant, si les résultats annuels ne sont pas nécessaires, xhydro.cc.produce_horizon peut contourner les étapes 2 à 4 et éviter beaucoup de tracas. Il le fait en supprimant l’axe time et en le remplaçant par une dimension horizon qui représente une tranche de temps. Dans le cas des indicateurs saisonniers ou mensuels, une dimension correspondante season ou month est également ajoutée.
Nous allons calculer le débit moyen estival (un indicateur annuel) et les débits moyens mensuels.
[23]:
indicators = [
# Mean summer flow
xclim.core.indicator.Indicator.from_dict(
data={
"base": "stats",
"input": {"da": "q"},
"parameters": {"op": "mean", "indexer": {"month": [6, 7, 8]}},
},
identifier="qmoy_summer",
module="hydro",
),
# Mean monthly flow
xclim.core.indicator.Indicator.from_dict(
data={
"base": "stats",
"input": {"da": "q"},
"parameters": {"op": "mean", "freq": "MS"},
},
identifier="qmoy_monthly",
module="hydro",
),
]
ds_indicators = xh.cc.produce_horizon(
best_simulation, indicators=indicators, periods=["1991", "2020"]
)
ds_indicators
[23]:
<xarray.Dataset> Size: 316B
Dimensions: (horizon: 1, month: 12)
Coordinates:
* horizon (horizon) <U9 36B '1991-2020'
* month (month) <U3 144B 'JAN' 'FEB' 'MAR' ... 'OCT' 'NOV' 'DEC'
subbasin_id <U1 4B '1'
elevation float32 4B 222.6
drainage_area float64 8B 585.6
centroid_longitude float64 8B -71.26
centroid_latitude float64 8B 46.45
Data variables:
qmoy_summer (horizon) float64 8B 9.589
qmoy_monthly (horizon, month) float64 96B 5.919 4.565 ... 12.27 9.125
Attributes:
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-03-31T14:36:41 by Raven 4.1
description: Standard Output
references: Craig J.R. and the Raven Development Team Raven us...
model_id: GR4JCN
Raven_version: 4.1
RavenPy_version: 0.20.0
cat:xrfreq: fx
cat:frequency: fx
cat:processing_level: horizons
cat:variable: ('qmoy_monthly',)Analyse fréquencielle¶
INFO
Pour plus d’informations sur cette section et les options disponibles, consultez le Notebook d’analyse fréquencielle locale.
Une analyse fréquencielle suit généralement ces étapes :
Obtenir les données brutes nécessaires à l’analyse, telles que les maximums annuels, via
xhydro.indicators.get_yearly_op.Appeler
xhfa.local.fitpour obtenir les paramètres d’un nombre spécifié de distributions, telles que Gumbel, GEV et Pearson-III.(Facultatif) Appeler
xhfa.local.criteriapour obtenir les paramètres de qualité d’ajustement.Appeler
xhfa.local.parametric_quantilespour obtenir les niveaux de retour.
Nous allons calculer les maximums annuels sur 20 et 100 ans, ainsi que le minimum des débits estivaux sur 7 jours pour une période de 2 ans.
[24]:
qref_max = xh.indicators.get_yearly_op(
best_simulation,
op="max",
timeargs={"annual": {}},
missing="pct",
missing_options={"tolerance": 0.15},
)
qref_min = xh.indicators.get_yearly_op(
best_simulation,
op="min",
window=7,
timeargs={"summer": {"date_bounds": ["05-01", "11-30"]}},
missing="pct",
missing_options={"tolerance": 0.15},
)
[25]:
ax = plt.figure(figsize=(10, 5))
qref_max.q_max_annual.dropna("time", how="all").plot()
qref_min.q7_min_summer.dropna("time", how="all").plot()
[25]:
[<matplotlib.lines.Line2D at 0x7f5f920e8440>]
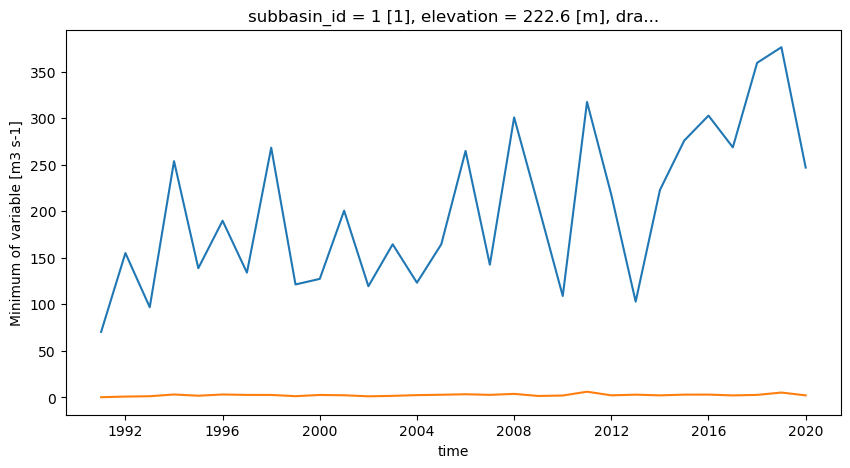
[26]:
params_max = xhfa.local.fit(
qref_max,
distributions=["genextreme", "gumbel_r", "norm", "pearson3"],
method="MLE",
min_years=20,
).compute()
params_min = xhfa.local.fit(
qref_min,
distributions=["genextreme", "gumbel_r", "norm", "pearson3"],
method="MLE",
min_years=20,
).compute()
params_max
[26]:
<xarray.Dataset> Size: 436B
Dimensions: (scipy_dist: 4, dparams: 4)
Coordinates:
* scipy_dist (scipy_dist) <U10 160B 'genextreme' ... 'pearson3'
* dparams (dparams) <U5 80B 'c' 'skew' 'loc' 'scale'
horizon <U9 36B '1991-2020'
subbasin_id <U1 4B '1'
elevation float32 4B 222.6
drainage_area float64 8B 585.6
centroid_longitude float64 8B -71.26
centroid_latitude float64 8B 46.45
Data variables:
q_max_annual (scipy_dist, dparams) float64 128B 0.08161 nan ... 87.46
Attributes: (12/13)
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-03-31T14:36:41 by Raven 4.1
description: Standard Output
references: Craig J.R. and the Raven Development Team Raven us...
model_id: GR4JCN
... ...
RavenPy_version: 0.20.0
cat:xrfreq: YS-JAN
cat:frequency: yr
cat:processing_level: indicators
cat:variable: ('q_max_annual',)
cat:id: Bien que non infaillible, le meilleur ajustement peut être identifié en utilisant le Critère d’Information Bayésien.
[27]:
criteria_max = xhfa.local.criteria(qref_max, params_max)
criteria_max = str(
criteria_max.isel(
scipy_dist=criteria_max.q_max_annual.sel(criterion="bic").argmin(dim="scipy_dist").values
).scipy_dist.values
) # Get the best fit as a string
print(f"Best distribution for the annual maxima: {criteria_max}")
criteria_min = xhfa.local.criteria(qref_min, params_min)
criteria_min = str(
criteria_min.isel(
scipy_dist=criteria_min.q7_min_summer.sel(criterion="bic").argmin(dim="scipy_dist").values
).scipy_dist.values
) # Get the best fit as a string
print(f"Best distribution for the summer 7-day minima: {criteria_min}")
Best distribution for the annual maxima: gumbel_r
Best distribution for the summer 7-day minima: gumbel_r
Les fonctions de traçage viendront éventuellement à xhydro.frequency_analysis, mais elles sont actuellement en cours de développement et sont cachées par défaut. Jusqu’à ce qu’une fonction publique soit ajoutée à la libraries, ces fonctions cachées peuvent toujours être appelées pour illustrer les résultats.
[28]:
# Plotting
data_max = xhfa.local._prepare_plots(
params_max, xmin=1, xmax=1000, npoints=50, log=True
)
data_max["q_max_annual"].attrs["long_name"] = "q"
pp = xhfa.local._get_plotting_positions(qref_max[["q_max_annual"]])
ax = plt.figure(figsize=(10, 5))
data_max.q_max_annual.sel(scipy_dist=criteria_max).plot(color="k")
plt.xscale("log")
pp.plot.scatter(
x="q_max_annual_pp",
y="q_max_annual",
color="k",
)
[28]:
<matplotlib.collections.PathCollection at 0x7f5f920b6a50>
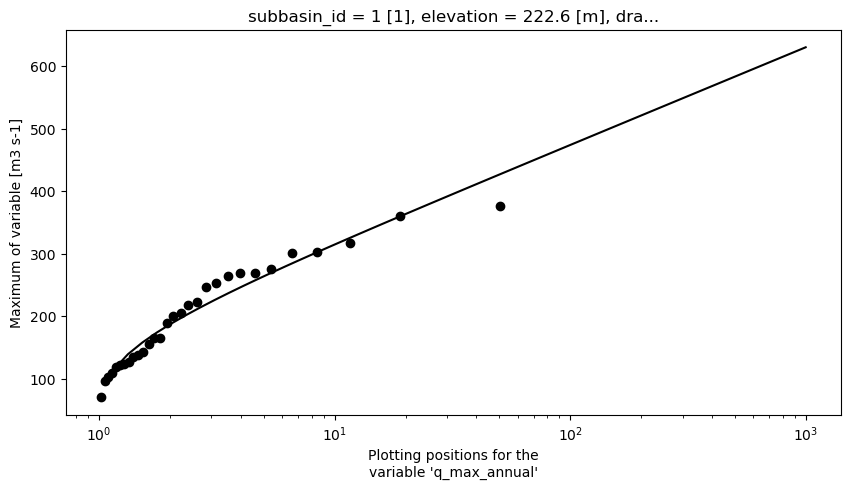
[29]:
# Plotting
data_min = xhfa.local._prepare_plots(
params_min, xmin=1, xmax=1000, npoints=50, log=True
)
data_min["q7_min_summer"].attrs["long_name"] = "q"
pp = xhfa.local._get_plotting_positions(qref_min[["q7_min_summer"]])
ax = plt.figure(figsize=(10, 5))
data_min.q7_min_summer.sel(scipy_dist=criteria_min).plot(color="k")
plt.xscale("log")
pp.plot.scatter(
x="q7_min_summer_pp",
y="q7_min_summer",
color="k",
)
[29]:
<matplotlib.collections.PathCollection at 0x7f5f90358690>

[30]:
# Computation of return levels
rl_max = xhfa.local.parametric_quantiles(
params_max.sel(scipy_dist=criteria_max).expand_dims("scipy_dist"),
return_period=[20, 100],
).squeeze()
rl_min = xhfa.local.parametric_quantiles(
params_min.sel(scipy_dist=criteria_min).expand_dims("scipy_dist"),
return_period=[2],
mode="min",
).squeeze()
rl_max
[30]:
<xarray.Dataset> Size: 148B
Dimensions: (return_period: 2)
Coordinates:
* return_period (return_period) int64 16B 20 100
p_quantile (return_period) float64 16B 0.95 0.99
horizon <U9 36B '1991-2020'
scipy_dist <U8 32B 'gumbel_r'
subbasin_id <U1 4B '1'
elevation float32 4B 222.6
drainage_area float64 8B 585.6
centroid_longitude float64 8B -71.26
centroid_latitude float64 8B 46.45
Data variables:
q_max_annual (return_period) float64 16B 363.4 473.8
Attributes: (12/13)
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-03-31T14:36:41 by Raven 4.1
description: Standard Output
references: Craig J.R. and the Raven Development Team Raven us...
model_id: GR4JCN
... ...
RavenPy_version: 0.20.0
cat:xrfreq: YS-JAN
cat:frequency: yr
cat:processing_level: indicators
cat:variable: ('q_max_annual',)
cat:id: [31]:
print(
f"20-year annual maximum: {np.round(rl_max.q_max_annual.sel(return_period=20).values, 1)} m³/s"
)
print(
f"100-year annual maximum: {np.round(rl_max.q_max_annual.sel(return_period=100).values, 1)} m³/s"
)
print(
f"2-year minimum 7-day summer flow: {np.round(rl_min.q7_min_summer.values, 1)} m³/s"
)
20-year annual maximum: 363.4 m³/s
100-year annual maximum: 473.8 m³/s
2-year minimum 7-day summer flow: 2.4 m³/s
Simulations et indicateurs de débit futur¶
Données météorologiques futures¶
Maintenant que nous avons accès à un modèle hydrologique calé et à des indicateurs historiques, nous pouvons réaliser l’analyse d’impact des changements climatiques. Cet exemple utilisera un ensemble de modèles CMIP6 qui ont été débiaisés en utilisant ERA5-Land, pour assurer la cohérence avec le produit de référence. Plus précisément, nous utiliserons le jeu de données ESPO-G6-E5L, également hébergé sur PAVICS. Bien qu’il soit recommandé d’utiliser plusieurs scénarios d’émission, cet exemple se limitera à utiliser les simulations SSP2-4.5 provenant de 14 modèles climatiques.
Nous pouvons en grande partie réutiliser le même code que ci-dessus. Une différence est que les modèles climatiques utilisent souvent des calendriers personnalisés. Raven peut les gérer, mais il peut encore être nécessaire de les convertir en calendriers standard. L’argument convert_calendar_missing de format_input peut être utilisé à cet effet. Si « True », il interpolera linéairement les données de température et mettra 0 pour les précipitations pour les jours de calendrier qui sont ajoutés au jeu de données.
[32]:
models = [
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CAS_FGOALS-g3_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CMCC_CMCC-ESM2_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO-ARCCSS_ACCESS-CM2_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CSIRO_ACCESS-ESM1-5_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_DKRZ_MPI-ESM1-2-HR_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_INM_INM-CM5-0_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_MIROC_MIROC6_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_MPI-M_MPI-ESM1-2-LR_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_MRI_MRI-ESM2-0_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_NCC_NorESM2-LM_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_CNRM-CERFACS_CNRM-ESM2-1_ssp245_r1i1p1f2_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_NIMS-KMA_KACE-1-0-G_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_NOAA-GFDL_GFDL-ESM4_ssp245_r1i1p1f1_1950-2100.ncml",
"day_ESPO-G6-E5L_v1.0.0_CMIP6_ScenarioMIP_NAM_BCC_BCC-CSM2-MR_ssp245_r1i1p1f1_1950-2100.ncml",
]
Le code ci-dessous montrera comment procéder avec la première simulation, mais il pourrait être utilisé dans une boucle pour traiter les 14 simulations.
[33]:
model = models[0]
meteo_sim = xr.open_dataset(
f"https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/datasets/simulations/bias_adjusted/cmip6/ouranos/ESPO-G/ESPO-G6-E5Lv1.0.0/{model}",
engine="netcdf4",
chunks={"time": 365, "lon": 50, "lat": 50},
)
meteo_sim = xscen.spatial.subset(meteo_sim, method="shape", tile_buffer=2, shape=gdf)
# Add altitude data
meteo_sim = meteo_sim.assign_coords(
{"elevation": xr.ones_like(meteo_sim.pr.isel(time=0).drop_vars("time")) * 350}
)
meteo_sim["elevation"].attrs = {"units": "m"}
# Format the dataset
meteo_sim, config_meteo_sim = xh.modelling.format_input(
meteo_sim,
model="GR4JCN",
convert_calendar_missing=True,
save_as=notebook_folder / "_data" / f"meteo_sim0.nc",
)
Données de débit et indicateurs futurs¶
Encore une fois, le même code que précédemment peut être réutilisé ici, mais avec xhydro.modelling.hydrological_model. La principale différence est que les meilleurs paramètres peuvent être utilisés lors de la configuration du modèle hydrologique, et que les dates couvrent toute la période allant jusqu’en 2100.
Les indicateurs sont également calculés de manière similaire, avec l’ajout de l’utilisation d’une liste de périodes dans l’argument periods pour créer une dimension horizon, au lieu d’une période unique. La fonction xhydro.frequency_analysis.fit peut également accepter un argument periods.
Le code ci-dessous ne montrera encore qu’une seule simulation, mais pourrait être utilisé pour traiter les 14 simulations.
[34]:
from copy import deepcopy
import xhydro.modelling as xhm
[35]:
model_cfg = (
deepcopy(model_config) | config_meteo_sim
) # Update the config with the new information from the simulation file
model_cfg["parameters"] = np.array(best_parameters)
model_cfg["start_date"] = "1991-01-01"
model_cfg["end_date"] = "2099-12-31"
qsim = xhm.hydrological_model(model_cfg).run()
[36]:
plt.figure(figsize=(10, 5))
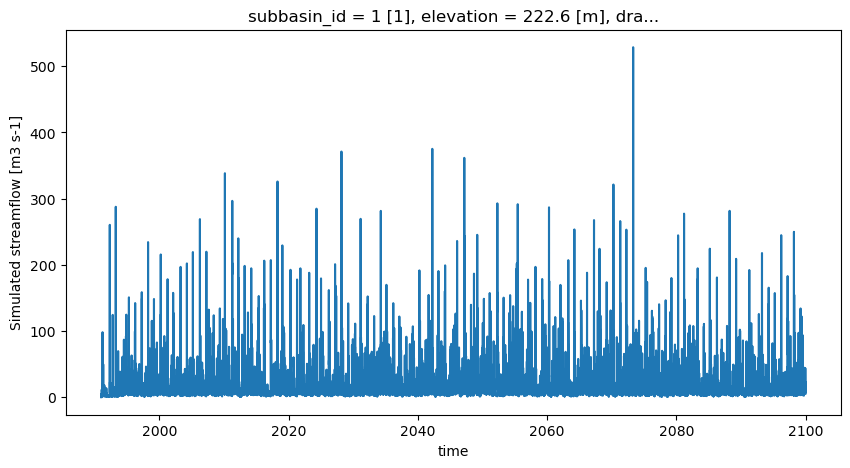
qsim.q.plot()
[36]:
[<matplotlib.lines.Line2D at 0x7f5f906d7e00>]
[37]:
# Non-frequential indicators
ds_indicators = xh.cc.produce_horizon(
qsim, indicators=indicators, periods=[["1991", "2020"], ["2070", "2099"]]
)
# Frequency analysis
qsim_max = xh.indicators.get_yearly_op(
qsim,
op="max",
timeargs={"annual": {}},
missing="pct",
missing_options={"tolerance": 0.15},
)
qsim_min = xh.indicators.get_yearly_op(
qsim,
op="min",
window=7,
timeargs={"summer": {"date_bounds": ["05-01", "11-30"]}},
missing="pct",
missing_options={"tolerance": 0.15},
)
params_max = xhfa.local.fit(
qsim_max,
distributions=["genextreme", "gumbel_r", "norm", "pearson3"],
method="MLE",
min_years=20,
periods=[["1991", "2020"], ["2070", "2099"]],
).compute()
params_min = xhfa.local.fit(
qsim_min,
distributions=["genextreme", "gumbel_r", "norm", "pearson3"],
method="MLE",
min_years=20,
periods=[["1991", "2020"], ["2070", "2099"]],
).compute()
criteria_max = xhfa.local.criteria(
qsim_max.sel(time=slice("1991", "2020")), params_max.sel(horizon="1991-2020")
)
criteria_max = str(
criteria_max.isel(
scipy_dist=criteria_max.q_max_annual.sel(criterion="bic").argmin(dim="scipy_dist").values
).scipy_dist.values
) # Get the best fit as a string
criteria_min = xhfa.local.criteria(
qsim_min.sel(time=slice("1991", "2020")), params_min.sel(horizon="1991-2020")
)
criteria_min = str(
criteria_min.isel(
scipy_dist=criteria_min.q7_min_summer.sel(criterion="bic").argmin(dim="scipy_dist").values
).scipy_dist.values
) # Get the best fit as a string
# Computation of return levels
rl_max = xhfa.local.parametric_quantiles(
params_max.sel(scipy_dist=criteria_max).expand_dims("scipy_dist"),
return_period=[20, 100],
).squeeze()
rl_min = xhfa.local.parametric_quantiles(
params_min.sel(scipy_dist=criteria_min).expand_dims("scipy_dist"),
return_period=[2],
mode="min",
).squeeze()
# Combine all indicators
ds_indicators = xr.merge([ds_indicators, rl_max, rl_min], compat="override")
ds_indicators
[37]:
<xarray.Dataset> Size: 568B
Dimensions: (horizon: 2, month: 12, return_period: 2)
Coordinates:
* horizon (horizon) <U9 72B '1991-2020' '2070-2099'
* month (month) <U3 144B 'JAN' 'FEB' 'MAR' ... 'OCT' 'NOV' 'DEC'
* return_period (return_period) int64 16B 20 100
p_quantile (return_period) float64 16B 0.95 0.99
subbasin_id <U1 4B '1'
elevation float32 4B 222.6
drainage_area float64 8B 585.6
centroid_longitude float64 8B -71.26
centroid_latitude float64 8B 46.45
scipy_dist <U8 32B 'gumbel_r'
Data variables:
qmoy_summer (horizon) float64 16B 9.707 8.611
qmoy_monthly (horizon, month) float64 192B 7.359 6.124 ... 11.74
q_max_annual (return_period, horizon) float64 32B 325.4 ... 437.9
q7_min_summer (horizon) float64 16B 2.109 1.983
Attributes:
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-03-31T14:40:01 by Raven 4.1
description: Standard Output
references: Craig J.R. and the Raven Development Team Raven us...
model_id: GR4JCN
Raven_version: 4.1
RavenPy_version: 0.20.0
cat:xrfreq: fx
cat:frequency: fx
cat:processing_level: horizons
cat:variable: ('qmoy_monthly',)Impacts des changements climatiques¶
INFO
Pour plus d’informations sur cette section et les options disponibles, consultez le Notebook d’analyse de l’impact des changements climatiques.
Cet exemple gardera l’analyse de l’impact des changements climatiques relativement simple.
Calculez la différence entre les périodes future et de référence en utilisant
xhydro.cc.compute_deltas.Utilisez ces différences pour calculer les statistiques d’ensemble en utilisant
xhydro.cc.ensemble_stats: percentiles de l’ensemble et accord entre les modèles climatiques.
[38]:
# Differences
deltas = xh.cc.compute_deltas(
ds_indicators, reference_horizon="1991-2020", kind="%", rename_variables=False
).isel(horizon=-1)
# Save the results
deltas.to_netcdf(notebook_folder / "_data" / f"deltas_sim0.nc")
deltas.squeeze()
[38]:
<xarray.Dataset> Size: 404B
Dimensions: (month: 12, return_period: 2)
Coordinates:
* month (month) <U3 144B 'JAN' 'FEB' 'MAR' ... 'OCT' 'NOV' 'DEC'
* return_period (return_period) int64 16B 20 100
p_quantile (return_period) float64 16B 0.95 0.99
subbasin_id <U1 4B '1'
elevation float32 4B 222.6
drainage_area float64 8B 585.6
centroid_longitude float64 8B -71.26
centroid_latitude float64 8B 46.45
horizon <U9 36B '2070-2099'
scipy_dist <U8 32B 'gumbel_r'
Data variables:
qmoy_summer float64 8B -11.29
qmoy_monthly (month) float64 96B 14.88 10.29 61.14 ... 22.37 24.68
q_max_annual (return_period) float64 16B 4.637 7.371
q7_min_summer float64 8B -5.966
Attributes:
Conventions: CF-1.6
featureType: timeSeries
history: Created on 2026-03-31T14:40:01 by Raven 4.1
description: Standard Output
references: Craig J.R. and the Raven Development Team Raven us...
model_id: GR4JCN
Raven_version: 4.1
RavenPy_version: 0.20.0
cat:xrfreq: fx
cat:frequency: fx
cat:processing_level: deltas
cat:variable: ('qmoy_monthly',)Il existe de nombreuses façons de créer l’ensemble lui-même. Si vous utilisez un dictionnaire de jeux de données, la clé sera utilisée pour nommer chaque élément de la nouvelle dimension realization. Cela peut être très utile lorsque l’on effectue des analyses plus détaillées ou lorsque l’on souhaite pondérer les différents modèles en fonction, par exemple, du nombre de simulations disponibles. Dans notre cas, puisque nous souhaitons seulement calculer des statistiques d’ensemble, nous pouvons simplifier et fournir simplement une liste.
[39]:
import pooch
# Acquire deltas for the other 13 simulations
from xhydro.testing.helpers import ( # In-house function to access xhydro-testdata
deveraux,
)
deltas_files = deveraux().fetch("use_case/deltas.zip", processor=pooch.Unzip())
deltas_files = xclim.ensembles.create_ensemble(deltas_files)
# Fix variable names and combine with the file we just created
deltas_files = deltas_files.rename(
{"streamflow_max_annual": "q_max_annual", "streamflow7_min_summer": "q7_min_summer"}
)
deltas_sim0 = xr.open_dataset(
notebook_folder / "_data" / f"deltas_sim0.nc"
).assign_coords({"realization": 13})
deltas_files = xr.concat([deltas_files, deltas_sim0], dim="realization")
clear_output(wait=False)
[40]:
# Statistics to compute
statistics = {
"ensemble_percentiles": {"values": [10, 25, 50, 75, 90], "split": False},
"robustness_fractions": {"test": None},
}
ens_stats = xh.cc.ensemble_stats(deltas_files, statistics)
ens_stats
[40]:
<xarray.Dataset> Size: 2kB
Dimensions: (percentiles: 5, month: 12, return_period: 2)
Coordinates:
* percentiles (percentiles) int64 40B 10 25 50 75 90
* month (month) <U3 144B 'JAN' 'FEB' ... 'NOV' 'DEC'
* return_period (return_period) int64 16B 20 100
p_quantile (return_period) float64 16B 0.95 0.99
basin_name <U7 28B 'sub_001'
horizon <U9 36B '2070-2099'
subbasin_id <U1 4B '1'
elevation float32 4B 222.6
drainage_area float64 8B 585.6
centroid_longitude float64 8B -71.26
centroid_latitude float64 8B 46.45
Data variables: (12/32)
qmoy_summer (percentiles) float64 40B -14.0 ... 19.14
qmoy_monthly (month, percentiles) float64 480B dask.array<chunksize=(12, 5), meta=np.ndarray>
q_max_annual (return_period, percentiles) float64 80B dask.array<chunksize=(2, 5), meta=np.ndarray>
q7_min_summer (percentiles) float64 40B -28.54 ... 11.68
qmoy_summer_changed float64 8B 1.0
qmoy_summer_positive float64 8B 0.5714
... ...
q7_min_summer_positive float64 8B 0.2143
q7_min_summer_changed_positive float64 8B 0.2143
q7_min_summer_negative float64 8B 0.7857
q7_min_summer_changed_negative float64 8B 0.7857
q7_min_summer_valid float64 8B 1.0
q7_min_summer_agree float64 8B 0.7857
Attributes:
cat:xrfreq: fx
cat:frequency: fx
cat:processing_level: ensemble
cat:variable: qmoy_monthly
ensemble_size: 4[41]:
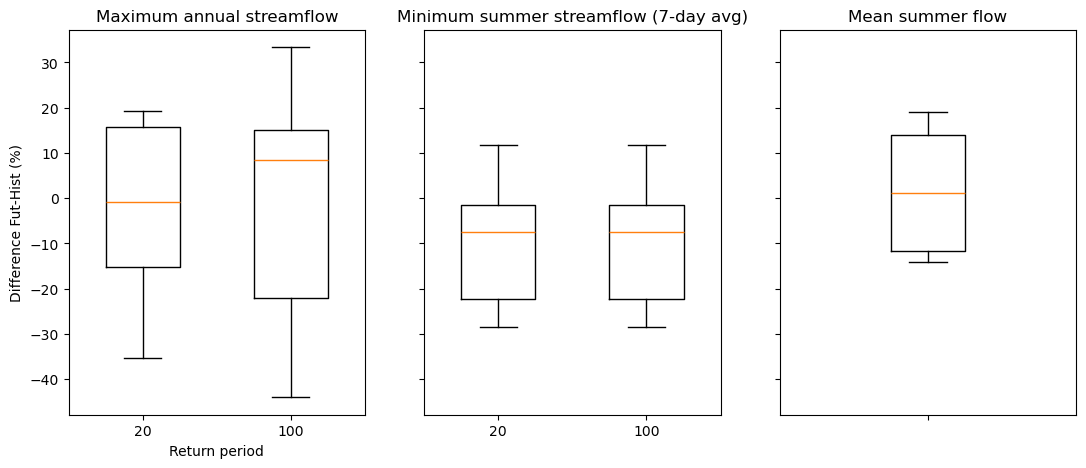
# Recreate the boxplots based on the computed percentiles
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(13, 5), sharey=True)
ax = plt.subplot(1, 3, 1)
for i, rp in enumerate(ens_stats.return_period.values):
stats = [
{
"label": rp,
"med": ens_stats.q_max_annual.sel(percentiles=50, return_period=rp).values,
"q1": ens_stats.q_max_annual.sel(percentiles=25, return_period=rp).values,
"q3": ens_stats.q_max_annual.sel(percentiles=75, return_period=rp).values,
"whislo": ens_stats.q_max_annual.sel(
percentiles=10, return_period=rp
).values,
"whishi": ens_stats.q_max_annual.sel(
percentiles=90, return_period=rp
).values,
}
]
ax.bxp(stats, showfliers=False, positions=[i], widths=0.5)
ax.set_title("Maximum annual streamflow")
plt.xlabel("Return period")
plt.ylabel("Difference Fut-Hist (%)")
ax = plt.subplot(1, 3, 2)
for i, rp in enumerate(ens_stats.return_period.values):
stats = [
{
"label": rp,
"med": ens_stats.q7_min_summer.sel(percentiles=50).values,
"q1": ens_stats.q7_min_summer.sel(percentiles=25).values,
"q3": ens_stats.q7_min_summer.sel(percentiles=75).values,
"whislo": ens_stats.q7_min_summer.sel(percentiles=10).values,
"whishi": ens_stats.q7_min_summer.sel(percentiles=90).values,
}
]
ax.bxp(stats, showfliers=False, positions=[i], widths=0.5)
ax.set_title("Minimum summer streamflow (7-day avg)")
plt.xlabel("")
ax = plt.subplot(1, 3, 3)
stats = [
{
"label": "",
"med": ens_stats.qmoy_summer.sel(percentiles=50).values,
"q1": ens_stats.qmoy_summer.sel(percentiles=25).values,
"q3": ens_stats.qmoy_summer.sel(percentiles=75).values,
"whislo": ens_stats.qmoy_summer.sel(percentiles=10).values,
"whishi": ens_stats.qmoy_summer.sel(percentiles=90).values,
}
]
ax.bxp(stats, showfliers=False, positions=[i], widths=0.25)
ax.set_title("Mean summer flow")
plt.show()
[42]:
print(
f"Fraction of simulations with a positive change (maximum streamflow): {ens_stats.q_max_annual_positive.values}"
)
print(
f"Fraction of simulations with a positive change (minimum summer streamflow): {ens_stats.q7_min_summer_positive.values}"
)
print(
f"Fraction of simulations with a positive change (mean summer streamflow): {ens_stats.qmoy_summer_positive.values}"
)
Fraction of simulations with a positive change (maximum streamflow): [0.5 0.64285714]
Fraction of simulations with a positive change (minimum summer streamflow): 0.21428571428571427
Fraction of simulations with a positive change (mean summer streamflow): 0.5714285714285714